1. 背景
小明在使用文件系统的过程中发现上传一个文件夹花了半个小时,下载一个文件夹要花更长的时间,不可思议,确实下载速度应该远远大于上传速度的,我们来分析下问题出在哪
文件的情况:
- 文件大小: 6.3G
- 文件个数: 252494
- 小明使用文件系统作为容器的持久化存储
2. 性能分析思路
2.1. 理论值计算
一切分析从数据出发,首先看下正常应该是怎么样的
hdd 下一般磁盘 4k 随机写 iops为1000左右
- 测算依据
- 文件个数
- 文件大小
- 4k的iops 1000左右
- 测算过程
- 6.3G / 252494 平均每个文件大小 26k
- 对应的26k的iops 26/4=6.5 1000/6.5 = 153
也就是说理论上传时间需要28分钟 252494 / 153 / 60 = 28
2.2. 实际操作下看能不能复现
将文件系统挂载到跟有问题的环境网络环境差不多的虚拟机上
拷贝文件
2.2.1. 性能分析关注点
一切性能问题,要么是CPU计算不过来了,要么是内存满了(使用swap),要么是磁盘慢、网络繁忙
加粗的指标重点关注
- CPU、内存 文件系统的话服务端是MDS,传输过程中查看MDS的内存占用和CPU占用
- 磁盘压力
- ceph层面的io性能指标
- ceph -s输出中的 client.io
-
ceph osd perf sort -rnk 20 有没时延特别高的上百的
- 本地磁盘的io性能
- iostat
- r/s 读ops
- w/s 写ops
- rMB/s 读带宽
- wMB/s 写带宽
- await 时延
- %util 利用率
- iostat
- ceph层面的io性能指标
2.2.2. 开始分析
上传文件的过程中分析
2.2.2.1. ceph -s
client: 0 B/s rd, 3.5 MiB/s wr, 72 op/s rd, 461 op/s wr
关注这行,正常的hdd集群有压力的时候前两个数值其中一个在100以上,后面两个数值至少在1000以上,在上传过程都没超过,说明集群本身没问题
2.2.2.2. 查看mds服务
ceph fs status 可以看到哪个是主mds,请求只到主mds上
cephfs - 11 clients
======
+------+--------+--------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+--------+---------------+-------+-------+
| 0 | active | ceph01 | Reqs: 0 /s | 408k | 408k |
+------+--------+--------+---------------+-------+-------+
查看主mds cpu 内存等等信息 top 进去按大P 按cpu排序,按大M 按内存排序,一般单进程CPU使用率超过100就是不正常的表现,内存超过10%就是不正常的表现
实际环境CPU没超过百分之10 内存没超过百分之10
top -p 2727890 -H -b
top - 19:24:56 up 75 days, 2:37, 1 user, load average: 0.43, 0.66, 0.70
Threads: 23 total, 0 running, 23 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.2 sy, 0.0 ni, 99.4 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 39541984+total, 33606768+free, 42129292 used, 17222856 buff/cache
KiB Swap: 33554428 total, 33554428 free, 0 used. 35048332+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2727890 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:00.11 ceph-mds
2727952 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 13:30.88 log
2728015 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 75:51.41 msgr-worker-0
2728016 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 71:19.25 msgr-worker-1
2728017 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 67:40.65 msgr-worker-2
2728080 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:26.70 service
2728081 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:00.00 admin_socket
2728082 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:00.00 signal_handler
2728083 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 65:18.79 ms_dispatch
2728084 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:00.00 ms_local
2728085 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:27.69 safe_timer
2728086 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:00.00 fn_anonymous
2728089 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 7:20.45 safe_timer
2728090 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 1:10.62 ceph-mds
2728953 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 3:30.28 safe_timer
2730059 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:21.43 ms_dispatch
2730060 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 7:16.65 OpHistorySvc
2730061 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 390:42.70 ms_dispatch
2730063 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 7:26.51 mds_rank_progr
2730064 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 5:37.53 PQ_Finisher
2730065 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 0:59.75 safe_timer
2730066 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 653:34.07 fn_anonymous
2730068 ceph 20 0 6290512 1.3g 14148 S 0.0 0.4 18:55.23 md_submit
2.2.2.3. 查看ceph osd perf
osd perf是osd时延的展示ceph集群的网络时延+磁盘时延,正常在100之内,实际在10以内
ceph osd perf |sort -rnk 3
osd commit_latency(ms) apply_latency(ms)
9 0 0
8 0 0
7 0 0
6 0 0
5 0 0
4 0 0
3 0 0
23 0 0
2.2.2.4. 查看磁盘iostat
利用率很高 百分之90以上就算压力特别大,时延高于100就算比较高,实际环境都很小
iostat -hmx 2
avg-cpu: %user %nice %system %iowait %steal %idle
0.27 0.00 0.11 0.03 0.00 99.59
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda
0.00 0.00 0.00 6.00 0.00 0.56 190.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb
0.00 0.50 3.50 37.00 0.01 0.38 19.95 0.00 0.05 0.00 0.05 0.02 0.10
sde
0.00 0.00 2.00 14.00 0.01 0.12 16.75 0.01 0.62 5.00 0.00 0.62 1.00
以上几个点说明集群没问题了 问题只能出在客户端或者客户端与集群之间的网络
2.2.2.5. 网络
网络可以通过交换机监控,网口监控等方式,或者sar命令查看(粒度比较粗),实际操作比较麻烦,放在后面在查
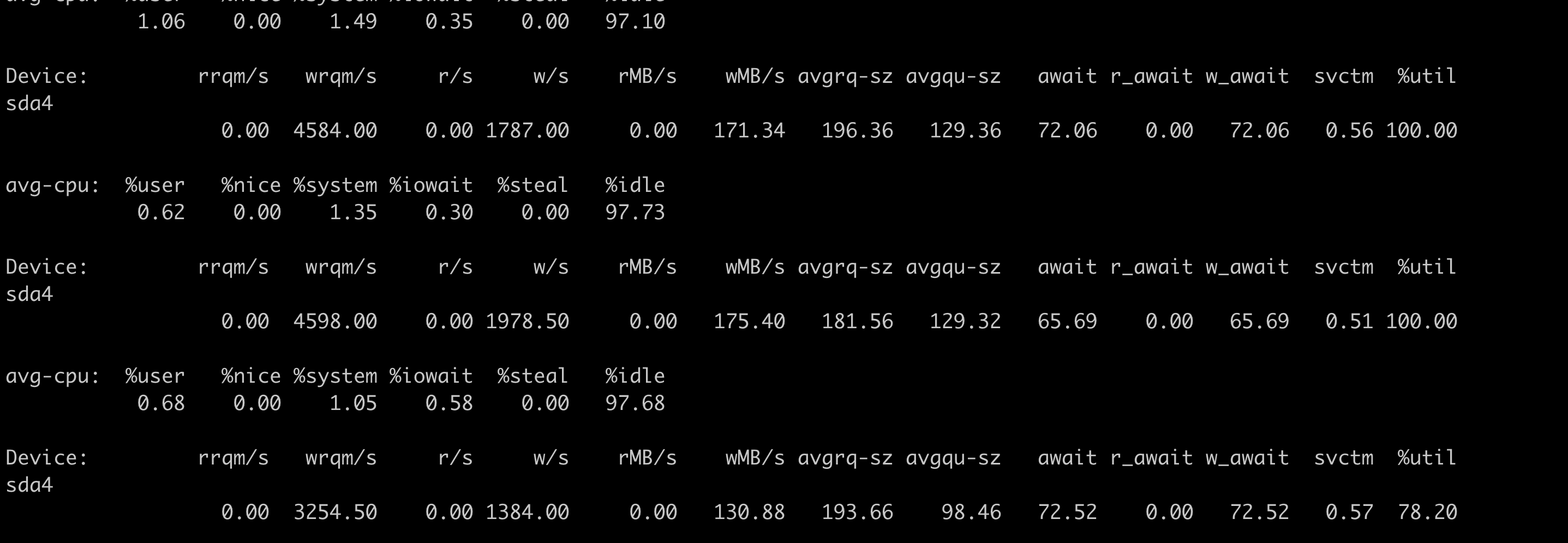
2.2.2.6. 客户端磁盘
iostat 查看到磁盘利用率百分百了,破案! 整个链路的瓶颈就是这里了,实际上这个磁盘io性能已经很高了,100多的带宽, 接近2000的iops,所以这个也是正常的,只不过集群没有压力,也就是说现在这个io速度是正常的,如果换更好的磁盘,例如ssd会更快。
3. 总结
- 通过理论数值判断快慢是否合适
- 通过io链路排查找出io瓶颈
最后,小明说的下载了半天没有复现,从服务端来看,如果太慢集群会有满请求,集群有满请求ceph-mgr会有记录,查看集群一切正常,所以问题应该出在客户端/网络,下次再出现就可以在这两块优先下手排查了