- 1. 概述
- 2. 调度流程
- 3. Pod调度流程
- 4. 参考
1. 概述
使用hami的过程中经常会出现Pod被创建出来Pending的问题,犹以如下两个问题为著
- Pod UnexpectedAdmissionError
- Pod Pending
介于此,展开这部分代码的粗略走读,旨在说明调度过程中各组件的交互,以及资源的计算方式,其他细节会有所遗漏
2. 调度流程
看代码之前可以先看下官方文档说明,大体上比较明确 
细节上可以分为三个阶段
- 准备阶段: 图上可以看出有一些依赖条件,例如要有mutating webhook, device-plugin等等,所以这个阶段主要分析下依赖条件的准备, 只有在服务首次启动时需要
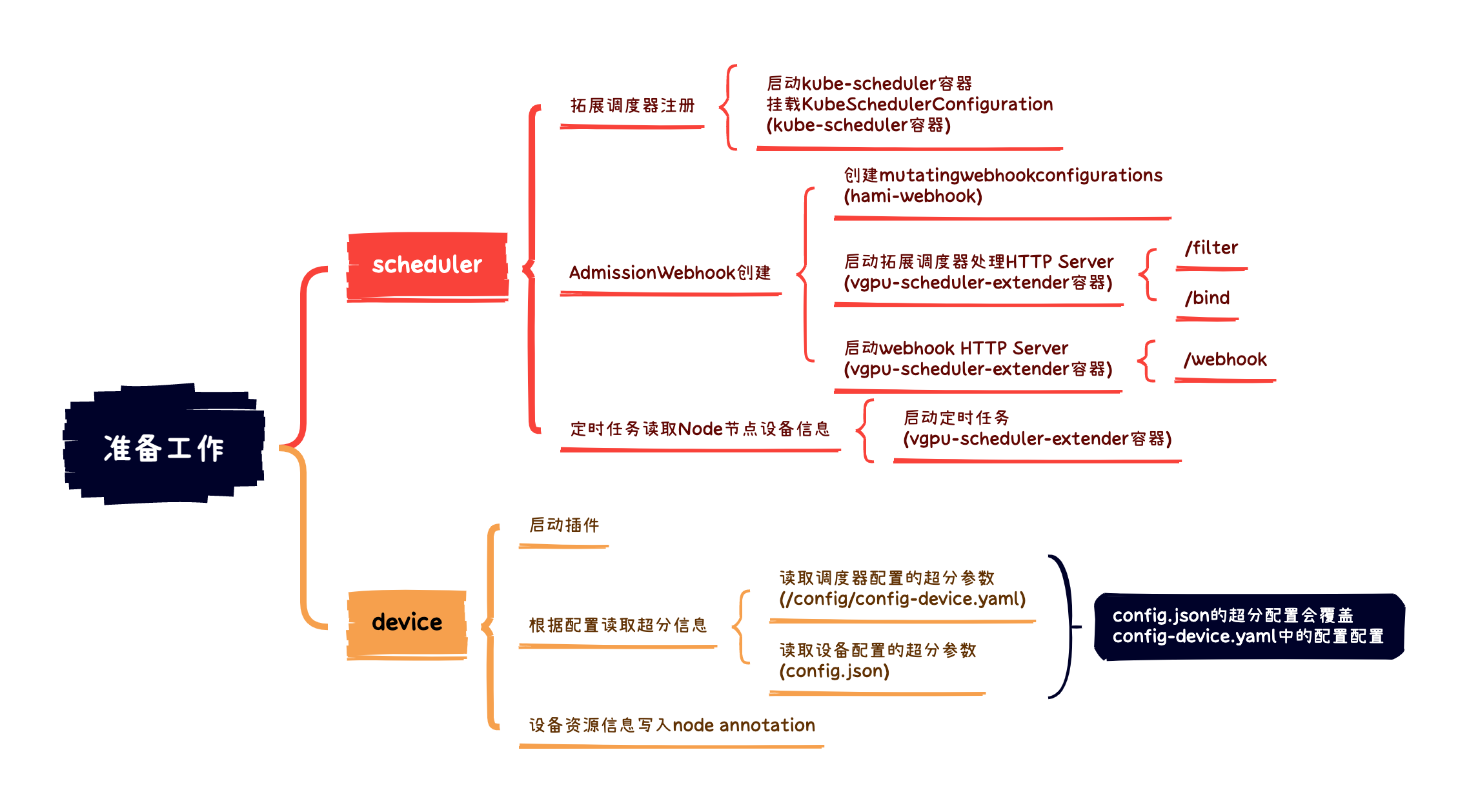
- pod调度阶段: 准备过程完成之后pod进入处理流程,完成调度
- Pod启动阶段: pod如何与node上的gpu进行交互等
本文会着重分析准备阶段,主要内容为调度分析
3. Pod调度流程
- 用户发送创建Pod请求到kube-apiserver
- 触发adminssion webhook,更新pod中schedulerName
- kube-apiserver根据schedulerName将请求发送给调度器处理
- 调度器处理
- 收集Node device信息 – 通过node annotation收集,数据来自daemonSet
hami-device-plugin定时写入 - 根据设备信息以及pod的limit信息进行打分,选出最高分的node
- 将pod和node进行绑定完成绑定,进行pod创建
- 收集Node device信息 – 通过node annotation收集,数据来自daemonSet
常见的几个问题排查及处理
Pod UnexpectedAdmissionError
pod创建状态显示 UnexpectedAdmissionError
了解流程之后,可以知道这个错误代表kube-apiserver调用拓展调度器失败,可能有两个原因,其他情况具体排查需要看 kube-apiserver日志
- 通信异常: 从kube-apiserver到拓展调度器的https端口不通,有几种可能
- dns无法解析
- 跨节点通信有问题
- 拓展调度器的服务异常
- TLS验证错误: 一般会显示
webhook x509: certificate signed by unknown authority,helmchart部署时有一个jobs.batchhami-vgpu.admission-pathch, 如果没有运行完成会出现这样的问题
调度问题
容器一直在 pending 状态,使用 kubectl describe命令可以看到具体原因,主要有以下几个
card Insufficient remaining memorycalcScore:node not fit pod
主要原因一般会是确实资源不足,或者配置错误,配置错误是指 devicememoryscaling 配置未符合预期,有两个地方可以配置, 优先级为节点配置大于全局配置,容易发生问题的地方在于 name需要和kubectl get node显示的nodename一致才能生效
- 全局配置
k get cm hami-scheduler-device
deviceMemoryScaling: 3
- 节点配置
k get cm hami-device-plugin
{
"nodeconfig": [
{
"name": "node1",
"devicememoryscaling": 3,
"devicesplitcount": 10,
"migstrategy":"none",
"filterdevices": {
"uuid": [],
"index": []
}
}
]
}
3.1. MutatingWebhook
K8s提供了adminssionWebhook资源, 以k8s资源操作为触发器,触发hook,用途最广泛的为针对Pod创建做拦截,对Pod做yaml注入,具体的例如增加init容器注入文件等等
3.1.1. webhook配置
hami-webhook
k get mutatingwebhookconfigurations.admissionregistration.k8s.io hami-webhook -o yaml
apiVersion: admissionregistration.k8s.io/v1
kind: MutatingWebhookConfiguration
metadata:
annotations:
meta.helm.sh/release-name: hami
meta.helm.sh/release-namespace: kube-system
creationTimestamp: "2024-12-10T03:50:37Z"
generation: 5
labels:
app.kubernetes.io/managed-by: Helm
name: hami-webhook
resourceVersion: "2307810"
uid: 2cdcebe4-f561-429f-9480-701e65980687
webhooks:
- admissionReviewVersions:
- v1beta1
clientConfig:
caBundle: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUJkakNDQVJ5Z0F3SUJBZ0lSQUxjd2FQMjUrMlphdGhTTlFMcG1qT0V3Q2dZSUtvWkl6ajBFQXdJd0R6RU4KTUFzR0ExVUVDaE1FYm1sc01UQWdGdzB5TkRFeU1EWXdOekV4TVRWYUdBOHlNVEkwTVRFeE1qQTNNVEV4TlZvdwpEekVOTUFzR0ExVUVDaE1FYm1sc01UQlpNQk1HQnlxR1NNNDlBZ0VHQ0NxR1NNNDlBd0VIQTBJQUJDUnlXUDdYCkRmT2N4NEVTMVRYaUs0dnFFU2wrcUFHYjI2YzNrOEdMWlZTL1lHaFpLZVVxaEgydVRhTFdWTW1hZVJFbkxqM0cKSStMVFRVTTR6SVhEUld5alZ6QlZNQTRHQTFVZER3RUIvd1FFQXdJQ0JEQVRCZ05WSFNVRUREQUtCZ2dyQmdFRgpCUWNEQVRBUEJnTlZIUk1CQWY4RUJUQURBUUgvTUIwR0ExVWREZ1FXQkJTcVV4bWpGa29YUlpRK0xXVzBNM1pJCnMzck1wakFLQmdncWhrak9QUVFEQWdOSUFEQkZBaUJSY2VRL2tJVkR2VTV3Vjl0K3NRWm93TmFhTWhIMTV5K2sKT3VrR0FlRGVtQUloQUxDZzFrM0JQZUJBNG8reWY5emxvVjM2VEk2RHUzaGdMT1B3MXhaZkFvcDMKLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
service:
name: hami-scheduler
namespace: kube-system
path: /webhook
port: 443
failurePolicy: Ignore
matchPolicy: Equivalent
name: vgpu.hami.io
namespaceSelector:
matchExpressions:
- key: hami.io/webhook
operator: NotIn
values:
- ignore
objectSelector:
matchExpressions:
- key: hami.io/webhook
operator: NotIn
values:
- ignore
reinvocationPolicy: Never
rules:
- apiGroups:
- ""
apiVersions:
- v1
operations:
- CREATE
resources:
- pods
scope: '*'
sideEffects: None
timeoutSeconds: 10
当pod创建时,调用 https://hami-scheduler.kube-system:443/webhook 做tls校验,CA为 caBundle 配置
当命名空间有 hami.io/webhook: ignore 的标签时不触发
3.1.2. webhook Server实现
需要实现一个tls的Http Server, 且提供 /webhook 接口
cmd/scheduler/main.go:84
func start() {
...
router.POST("/webhook", routes.WebHookRoute())
WebHookRoute 需要实现 sigs.k8s.io/controller-runtime@v0.16.3/pkg/webhook/admission/webhook.go:98
pkg/scheduler/webhook.go:52
pod := &corev1.Pod{}
err := h.decoder.Decode(req, pod)
if err != nil {
klog.Errorf("Failed to decode request: %v", err)
return admission.Errored(http.StatusBadRequest, err)
}
if len(pod.Spec.Containers) == 0 {
klog.Warningf(template+" - Denying admission as pod has no containers", req.Namespace, req.Name, req.UID)
return admission.Denied("pod has no containers")
}
klog.Infof(template, req.Namespace, req.Name, req.UID)
hasResource := false
for idx, ctr := range pod.Spec.Containers {
c := &pod.Spec.Containers[idx]
if ctr.SecurityContext != nil {
if ctr.SecurityContext.Privileged != nil && *ctr.SecurityContext.Privileged {
klog.Warningf(template+" - Denying admission as container %s is privileged", req.Namespace, req.Name, req.UID, c.Name)
continue
}
}
for _, val := range device.GetDevices() {
found, err := val.MutateAdmission(c, pod)
if err != nil {
klog.Errorf("validating pod failed:%s", err.Error())
return admission.Errored(http.StatusInternalServerError, err)
}
hasResource = hasResource || found
}
}
if !hasResource {
klog.Infof(template+" - Allowing admission for pod: no resource found", req.Namespace, req.Name, req.UID)
//return admission.Allowed("no resource found")
} else if len(config.SchedulerName) > 0 {
pod.Spec.SchedulerName = config.SchedulerName
if pod.Spec.NodeName != "" {
klog.Infof(template+" - Pod already has node assigned", req.Namespace, req.Name, req.UID)
return admission.Denied("pod has node assigned")
}
}
marshaledPod, err := json.Marshal(pod)
if err != nil {
klog.Errorf(template+" - Failed to marshal pod, error: %v", req.Namespace, req.Name, req.UID, err)
return admission.Errored(http.StatusInternalServerError, err)
}
return admission.PatchResponseFromRaw(req.Object.Raw, marshaledPod)
主要通过pod中容器的resource来判断是否要不要走拓展调度器
pkg/device/nvidia/device.go:246
func (dev *NvidiaGPUDevices) MutateAdmission(ctr *corev1.Container, p *corev1.Pod) (bool, error) {
/*gpu related */
priority, ok := ctr.Resources.Limits[corev1.ResourceName(dev.config.ResourcePriority)]
if ok {
ctr.Env = append(ctr.Env, corev1.EnvVar{
Name: util.TaskPriority,
Value: fmt.Sprint(priority.Value()),
})
}
_, resourceNameOK := ctr.Resources.Limits[corev1.ResourceName(dev.config.ResourceCountName)]
if resourceNameOK {
return resourceNameOK, nil
}
_, resourceCoresOK := ctr.Resources.Limits[corev1.ResourceName(dev.config.ResourceCoreName)]
_, resourceMemOK := ctr.Resources.Limits[corev1.ResourceName(dev.config.ResourceMemoryName)]
_, resourceMemPercentageOK := ctr.Resources.Limits[corev1.ResourceName(dev.config.ResourceMemoryPercentageName)]
if resourceCoresOK || resourceMemOK || resourceMemPercentageOK {
if dev.config.DefaultGPUNum > 0 {
ctr.Resources.Limits[corev1.ResourceName(dev.config.ResourceCountName)] = *resource.NewQuantity(int64(dev.config.DefaultGPUNum), resource.BinarySI)
resourceNameOK = true
}
}
if !resourceNameOK && dev.config.OverwriteEnv {
ctr.Env = append(ctr.Env, corev1.EnvVar{
Name: "NVIDIA_VISIBLE_DEVICES",
Value: "none",
})
}
return resourceNameOK, nil
}
主要比对pod的 Resources Limit中有没有包含 device-config.yaml 的配置,如果有走hami调度流程
deivce-config 以英伟达显卡为例
nvidia:
resourceCountName: nvidia.com/gpu
resourceMemoryName: nvidia.com/gpumem
resourceMemoryPercentageName: nvidia.com/gpumem-percentage
resourceCoreName: nvidia.com/gpucores
resourcePriorityName: nvidia.com/priority
overwriteEnv: false
defaultMemory: 0
defaultCores: 0
defaultGPUNum: 1
deviceSplitCount: 10
deviceMemoryScaling: 3
deviceCoreScaling: 3
确定走hami调度流程之后,通过Patch修改Pod schedulerName 为hami调度器的名称
3.2. 拓展k8s scheduler
KubeSchedulerConfiguration 拓展调度器可以通过实现拓展点进行调度器的拓展
3.2.1. KubeSchedulerConfiguration
k get cm hami-scheduler-newversion -o yaml
apiVersion: v1
data:
config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: hami-scheduler
extenders:
- urlPrefix: "https://127.0.0.1:443"
filterVerb: filter
bindVerb: bind
nodeCacheCapable: true
weight: 1
httpTimeout: 30s
enableHTTPS: true
tlsConfig:
insecure: true
managedResources:
- name: nvidia.com/gpu
ignoredByScheduler: true
- name: nvidia.com/gpumem
ignoredByScheduler: true
- name: nvidia.com/gpucores
ignoredByScheduler: true
- name: nvidia.com/gpumem-percentage
ignoredByScheduler: true
- name: nvidia.com/priority
ignoredByScheduler: true
- name: cambricon.com/vmlu
ignoredByScheduler: true
- name: hygon.com/dcunum
ignoredByScheduler: true
- name: hygon.com/dcumem
ignoredByScheduler: true
- name: hygon.com/dcucores
ignoredByScheduler: true
- name: iluvatar.ai/vgpu
ignoredByScheduler: true
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: hami
meta.helm.sh/release-namespace: kube-system
creationTimestamp: "2024-12-10T03:50:36Z"
labels:
app.kubernetes.io/component: hami-scheduler
app.kubernetes.io/instance: hami
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: hami
app.kubernetes.io/version: 2.4.1
helm.sh/chart: hami-2.4.1
name: hami-scheduler-newversion
namespace: kube-system
resourceVersion: "2316275"
uid: 3a61a72c-0bab-432f-b4d7-5c1ae46ee14d
拓展调度器通过拓展点进行拓展, 这里拓展了filter和bind
- filter: 找到最合适的node
- bind: 为pod创建一个binding资源
调度时会根据拓展点顺序来调用拓展调度器的实现,这里会先调用
https://127.0.0.1:443/filter 再调用 https://127.0.0.1:443/filter
3.2.2. 拓展调度器Http Server启动
cmd/scheduler/main.go:70
func start() {
device.InitDevices()
sher = scheduler.NewScheduler()
sher.Start()
defer sher.Stop()
// start monitor metrics
go sher.RegisterFromNodeAnnotations()
go initMetrics(config.MetricsBindAddress)
// start http server
router := httprouter.New()
router.POST("/filter", routes.PredicateRoute(sher))
router.POST("/bind", routes.Bind(sher))
3.2.3. filter实现
pkg/scheduler/routes/route.go:41
func PredicateRoute(s *scheduler.Scheduler) httprouter.Handle {
klog.Infoln("Into Predicate Route outer func")
return func(w http.ResponseWriter, r *http.Request, _ httprouter.Params) {
klog.Infoln("Into Predicate Route inner func")
checkBody(w, r)
var buf bytes.Buffer
body := io.TeeReader(r.Body, &buf)
var extenderArgs extenderv1.ExtenderArgs
var extenderFilterResult *extenderv1.ExtenderFilterResult
if err := json.NewDecoder(body).Decode(&extenderArgs); err != nil {
klog.Errorln("decode error", err.Error())
extenderFilterResult = &extenderv1.ExtenderFilterResult{
Error: err.Error(),
}
} else {
extenderFilterResult, err = s.Filter(extenderArgs)
if err != nil {
klog.Errorf("pod %v filter error, %v", extenderArgs.Pod.Name, err)
extenderFilterResult = &extenderv1.ExtenderFilterResult{
Error: err.Error(),
}
}
}
if resultBody, err := json.Marshal(extenderFilterResult); err != nil {
klog.Errorf("Failed to marshal extenderFilterResult: %+v, %+v",
err, extenderFilterResult)
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte(err.Error()))
} else {
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK)
w.Write(resultBody)
}
}
}
pkg/scheduler/scheduler.go:430
func (s *Scheduler) Filter(args extenderv1.ExtenderArgs) (*extenderv1.ExtenderFilterResult, error) {
klog.InfoS("begin schedule filter", "pod", args.Pod.Name, "uuid", args.Pod.UID, "namespaces", args.Pod.Namespace)
nums := k8sutil.Resourcereqs(args.Pod)
total := 0
for _, n := range nums {
for _, k := range n {
total += int(k.Nums)
}
}
if total == 0 {
klog.V(1).Infof("pod %v not find resource", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("does not request any resource"))
return &extenderv1.ExtenderFilterResult{
NodeNames: args.NodeNames,
FailedNodes: nil,
Error: "",
}, nil
}
annos := args.Pod.Annotations
s.delPod(args.Pod)
nodeUsage, failedNodes, err := s.getNodesUsage(args.NodeNames, args.Pod)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
if len(failedNodes) != 0 {
klog.V(5).InfoS("getNodesUsage failed nodes", "nodes", failedNodes)
}
nodeScores, err := s.calcScore(nodeUsage, nums, annos, args.Pod)
if err != nil {
err := fmt.Errorf("calcScore failed %v for pod %v", err, args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
if len((*nodeScores).NodeList) == 0 {
klog.V(4).Infof("All node scores do not meet for pod %v", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("no available node, all node scores do not meet"))
return &extenderv1.ExtenderFilterResult{
FailedNodes: failedNodes,
}, nil
}
klog.V(4).Infoln("nodeScores_len=", len((*nodeScores).NodeList))
sort.Sort(nodeScores)
m := (*nodeScores).NodeList[len((*nodeScores).NodeList)-1]
klog.Infof("schedule %v/%v to %v %v", args.Pod.Namespace, args.Pod.Name, m.NodeID, m.Devices)
annotations := make(map[string]string)
annotations[util.AssignedNodeAnnotations] = m.NodeID
annotations[util.AssignedTimeAnnotations] = strconv.FormatInt(time.Now().Unix(), 10)
for _, val := range device.GetDevices() {
val.PatchAnnotations(&annotations, m.Devices)
}
//InRequestDevices := util.EncodePodDevices(util.InRequestDevices, m.devices)
//supportDevices := util.EncodePodDevices(util.SupportDevices, m.devices)
//maps.Copy(annotations, InRequestDevices)
//maps.Copy(annotations, supportDevices)
s.addPod(args.Pod, m.NodeID, m.Devices)
err = util.PatchPodAnnotations(args.Pod, annotations)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
s.delPod(args.Pod)
return nil, err
}
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringSucceed, []string{m.NodeID}, nil)
res := extenderv1.ExtenderFilterResult{NodeNames: &[]string{m.NodeID}}
return &res, nil
}
这里核心逻辑主要有两步, 获取节点资源、根据节点已分配资源与总资源计算分数并选出一个最高分
3.2.3.1. 获取节点资源信息
pkg/scheduler/scheduler.go:241
func (s *Scheduler) getNodesUsage(nodes *[]string, task *corev1.Pod) (*map[string]*NodeUsage, map[string]string, error) {
overallnodeMap := make(map[string]*NodeUsage)
cachenodeMap := make(map[string]*NodeUsage)
failedNodes := make(map[string]string)
//for _, nodeID := range *nodes {
allNodes, err := s.ListNodes()
if err != nil {
return &overallnodeMap, failedNodes, err
}
for _, node := range allNodes {
nodeInfo := &NodeUsage{}
userGPUPolicy := config.GPUSchedulerPolicy
if task != nil && task.Annotations != nil {
if value, ok := task.Annotations[policy.GPUSchedulerPolicyAnnotationKey]; ok {
userGPUPolicy = value
}
}
nodeInfo.Node = node.Node
nodeInfo.Devices = policy.DeviceUsageList{
Policy: userGPUPolicy,
DeviceLists: make([]*policy.DeviceListsScore, 0),
}
for _, d := range node.Devices {
nodeInfo.Devices.DeviceLists = append(nodeInfo.Devices.DeviceLists, &policy.DeviceListsScore{
Score: 0,
Device: &util.DeviceUsage{
ID: d.ID,
Index: d.Index,
Used: 0,
Count: d.Count,
Usedmem: 0,
Totalmem: d.Devmem,
Totalcore: d.Devcore,
Usedcores: 0,
MigUsage: util.MigInUse{
Index: 0,
UsageList: make(util.MIGS, 0),
},
MigTemplate: d.MIGTemplate,
Mode: d.Mode,
Type: d.Type,
Numa: d.Numa,
Health: d.Health,
},
})
}
overallnodeMap[node.ID] = nodeInfo
}
podsInfo := s.ListPodsInfo()
for _, p := range podsInfo {
node, ok := overallnodeMap[p.NodeID]
if !ok {
continue
}
for _, podsingleds := range p.Devices {
for _, ctrdevs := range podsingleds {
for _, udevice := range ctrdevs {
for _, d := range node.Devices.DeviceLists {
deviceID := udevice.UUID
if strings.Contains(deviceID, "[") {
deviceID = strings.Split(deviceID, "[")[0]
}
if d.Device.ID == deviceID {
d.Device.Used++
d.Device.Usedmem += udevice.Usedmem
d.Device.Usedcores += udevice.Usedcores
if strings.Contains(udevice.UUID, "[") {
tmpIdx, Instance := util.ExtractMigTemplatesFromUUID(udevice.UUID)
if len(d.Device.MigUsage.UsageList) == 0 {
util.PlatternMIG(&d.Device.MigUsage, d.Device.MigTemplate, tmpIdx)
}
d.Device.MigUsage.UsageList[Instance].InUse = true
klog.V(3).Infoln("add mig usage", d.Device.MigUsage, "template=", d.Device.MigTemplate, "uuid=", d.Device.ID)
}
}
}
}
}
}
klog.V(5).Infof("usage: pod %v assigned %v %v", p.Name, p.NodeID, p.Devices)
}
s.overviewstatus = overallnodeMap
for _, nodeID := range *nodes {
node, err := s.GetNode(nodeID)
if err != nil {
// The identified node does not have a gpu device, so the log here has no practical meaning,increase log priority.
klog.V(5).InfoS("node unregistered", "node", nodeID, "error", err)
failedNodes[nodeID] = "node unregistered"
continue
}
cachenodeMap[node.ID] = overallnodeMap[node.ID]
}
s.cachedstatus = cachenodeMap
return &cachenodeMap, failedNodes, nil
}
获取node总的资源与已分配的资源, 首先获取node信息
pkg/scheduler/nodes.go:120
func (m *nodeManager) ListNodes() (map[string]*util.NodeInfo, error) {
m.mutex.RLock()
defer m.mutex.RUnlock()
return m.nodes, nil
}
这里用到了缓存,缓存节点信息,由 addNode 添加缓存
3.2.3.1.1. Node缓存
pkg/scheduler/nodes.go:46
func (m *nodeManager) addNode(nodeID string, nodeInfo *util.NodeInfo) {
if nodeInfo == nil || len(nodeInfo.Devices) == 0 {
return
}
m.mutex.Lock()
defer m.mutex.Unlock()
_, ok := m.nodes[nodeID]
if ok {
if len(nodeInfo.Devices) > 0 {
tmp := make([]util.DeviceInfo, 0, len(nodeInfo.Devices))
devices := device.GetDevices()
deviceType := ""
for _, val := range devices {
if strings.Contains(nodeInfo.Devices[0].Type, val.CommonWord()) {
deviceType = val.CommonWord()
}
}
for _, val := range m.nodes[nodeID].Devices {
if !strings.Contains(val.Type, deviceType) {
tmp = append(tmp, val)
}
}
m.nodes[nodeID].Devices = tmp
m.nodes[nodeID].Devices = append(m.nodes[nodeID].Devices, nodeInfo.Devices...)
}
} else {
m.nodes[nodeID] = nodeInfo
}
}
这里的主要逻辑在于 device.GetDevices() 获取设备信息
pkg/device/devices.go:81
func GetDevices() map[string]Devices {
return devices
}
device也是个缓存,后面再分析,首先看Node缓存是什么时候被调用的
pkg/scheduler/scheduler.go:155
func (s *Scheduler) RegisterFromNodeAnnotations() {
klog.V(5).Infoln("Scheduler into RegisterFromNodeAnnotations")
ticker := time.NewTicker(time.Second * 15)
for {
select {
case <-s.nodeNotify:
case <-ticker.C:
case <-s.stopCh:
return
}
labelSelector := labels.Everything()
if len(config.NodeLabelSelector) > 0 {
labelSelector = (labels.Set)(config.NodeLabelSelector).AsSelector()
}
rawNodes, err := s.nodeLister.List(labelSelector)
if err != nil {
klog.Errorln("nodes list failed", err.Error())
continue
}
var nodeNames []string
for _, val := range rawNodes {
nodeNames = append(nodeNames, val.Name)
for devhandsk, devInstance := range device.GetDevices() {
health, needUpdate := devInstance.CheckHealth(devhandsk, val)
klog.V(5).InfoS("device check health", "node", val.Name, "deviceVendor", devhandsk, "health", health, "needUpdate", needUpdate)
if !health {
err := devInstance.NodeCleanUp(val.Name)
// If the device is not healthy, the device is removed from the node.
// At the same time, this node needs to be removed from the cache.
if err != nil {
klog.Errorln("node cleanup failed", err.Error())
}
info, ok := s.nodes[val.Name]
if ok {
klog.Infof("node %v device %s:%v leave, %v remaining devices:%v", val.Name, devhandsk, info.ID, err, s.nodes[val.Name].Devices)
s.rmNodeDevice(val.Name, info, devhandsk)
continue
}
}
if !needUpdate {
continue
}
_, ok := util.HandshakeAnnos[devhandsk]
if ok {
tmppat := make(map[string]string)
tmppat[util.HandshakeAnnos[devhandsk]] = "Requesting_" + time.Now().Format("2006.01.02 15:04:05")
klog.V(4).InfoS("New timestamp", util.HandshakeAnnos[devhandsk], tmppat[util.HandshakeAnnos[devhandsk]], "nodeName", val.Name)
n, err := util.GetNode(val.Name)
if err != nil {
klog.Errorln("get node failed", err.Error())
continue
}
util.PatchNodeAnnotations(n, tmppat)
}
nodeInfo := &util.NodeInfo{}
nodeInfo.ID = val.Name
nodeInfo.Node = val
nodedevices, err := devInstance.GetNodeDevices(*val)
if err != nil {
continue
}
nodeInfo.Devices = make([]util.DeviceInfo, 0)
for _, deviceinfo := range nodedevices {
nodeInfo.Devices = append(nodeInfo.Devices, *deviceinfo)
}
s.addNode(val.Name, nodeInfo)
if s.nodes[val.Name] != nil && len(nodeInfo.Devices) > 0 {
klog.Infof("node %v device %s come node info=%s,%v total=%v", val.Name, devhandsk, nodeInfo.ID, nodeInfo.Devices, s.nodes[val.Name].Devices)
}
}
}
_, _, err = s.getNodesUsage(&nodeNames, nil)
if err != nil {
klog.Errorln("get node usage failed", err.Error())
}
}
}
启动了一个15s的定时任务,获取node信息维护node缓存
这里的核心逻辑在于 for devhandsk, devInstance := range device.GetDevices() 获取所有的device,主要是一些根据不同的设备注册了不同的handler, 根据注册的device获取显卡的资源信息 devInstance.GetNodeDevices
这里会通过注册的device(此环境为nvidia),调用到不同显卡的GetNodeDevices实现, device后面再做具体说明
pkg/device/nvidia/device.go:209
ffunc (dev *NvidiaGPUDevices) GetNodeDevices(n corev1.Node) ([]*util.DeviceInfo, error) {
devEncoded, ok := n.Annotations[RegisterAnnos]
if !ok {
return []*util.DeviceInfo{}, errors.New("annos not found " + RegisterAnnos)
}
nodedevices, err := util.DecodeNodeDevices(devEncoded)
if err != nil {
klog.ErrorS(err, "failed to decode node devices", "node", n.Name, "device annotation", devEncoded)
return []*util.DeviceInfo{}, err
}
if len(nodedevices) == 0 {
klog.InfoS("no nvidia gpu device found", "node", n.Name, "device annotation", devEncoded)
return []*util.DeviceInfo{}, errors.New("no gpu found on node")
}
for _, val := range nodedevices {
if val.Mode == "mig" {
val.MIGTemplate = make([]util.Geometry, 0)
for _, migTemplates := range dev.config.MigGeometriesList {
found := false
for _, migDevices := range migTemplates.Models {
if strings.Contains(val.Type, migDevices) {
found = true
break
}
}
if found {
val.MIGTemplate = append(val.MIGTemplate, migTemplates.Geometries...)
break
}
}
}
}
devDecoded := util.EncodeNodeDevices(nodedevices)
klog.V(5).InfoS("nodes device information", "node", n.Name, "nodedevices", devDecoded)
return nodedevices, nil
}
看到这里基本逻辑是 scheduler 通过定时器去读取node的annotation信息并将其维护再node缓存中,以供调度时使用
apiVersion: v1
kind: Node
metadata:
annotations:
...
hami.io/node-nvidia-register: 'GPU-7aebc545-cbd3-18a0-afce-76cae449702a,10,24576,300,NVIDIA-NVIDIA
GeForce RTX 3090,0,true:
又调用到了 device,这个我们待会儿再看,继续看谁调用的 RegisterFromNodeAnnotations
cmd/scheduler/main.go:70
func start() {
device.InitDevices()
sher = scheduler.NewScheduler()
sher.Start()
defer sher.Stop()
// start monitor metrics
go sher.RegisterFromNodeAnnotations()
go initMetrics(config.MetricsBindAddress)
调度器启动的时候就会调用,这里逻辑明确了,继续看刚刚的device
3.2.3.1.2. device
device通过 pkg/device/devices.go:85 进行初始化
func InitDevicesWithConfig(config *Config) {
devices = make(map[string]Devices)
DevicesToHandle = []string{}
devices[nvidia.NvidiaGPUDevice] = nvidia.InitNvidiaDevice(config.NvidiaConfig)
devices[cambricon.CambriconMLUDevice] = cambricon.InitMLUDevice(config.CambriconConfig)
devices[hygon.HygonDCUDevice] = hygon.InitDCUDevice(config.HygonConfig)
devices[iluvatar.IluvatarGPUDevice] = iluvatar.InitIluvatarDevice(config.IluvatarConfig)
devices[mthreads.MthreadsGPUDevice] = mthreads.InitMthreadsDevice(config.MthreadsConfig)
devices[metax.MetaxGPUDevice] = metax.InitMetaxDevice(config.MetaxConfig)
DevicesToHandle = append(DevicesToHandle, nvidia.NvidiaGPUCommonWord)
DevicesToHandle = append(DevicesToHandle, cambricon.CambriconMLUCommonWord)
DevicesToHandle = append(DevicesToHandle, hygon.HygonDCUCommonWord)
DevicesToHandle = append(DevicesToHandle, iluvatar.IluvatarGPUCommonWord)
DevicesToHandle = append(DevicesToHandle, mthreads.MthreadsGPUCommonWord)
DevicesToHandle = append(DevicesToHandle, metax.MetaxGPUCommonWord)
for _, dev := range ascend.InitDevices(config.VNPUs) {
devices[dev.CommonWord()] = dev
DevicesToHandle = append(DevicesToHandle, dev.CommonWord())
}
}
这里用的是nvidia所以主要看 InitNvidiaDevice 即可
pkg/device/devices.go:42
type Devices interface {
CommonWord() string
MutateAdmission(ctr *corev1.Container, pod *corev1.Pod) (bool, error)
CheckHealth(devType string, n *corev1.Node) (bool, bool)
NodeCleanUp(nn string) error
GetNodeDevices(n corev1.Node) ([]*util.DeviceInfo, error)
CheckType(annos map[string]string, d util.DeviceUsage, n util.ContainerDeviceRequest) (bool, bool, bool)
// CheckUUID is check current device id whether in GPUUseUUID or GPUNoUseUUID set, return true is check success.
CheckUUID(annos map[string]string, d util.DeviceUsage) bool
LockNode(n *corev1.Node, p *corev1.Pod) error
ReleaseNodeLock(n *corev1.Node, p *corev1.Pod) error
GenerateResourceRequests(ctr *corev1.Container) util.ContainerDeviceRequest
PatchAnnotations(annoinput *map[string]string, pd util.PodDevices) map[string]string
CustomFilterRule(allocated *util.PodDevices, request util.ContainerDeviceRequest, toAllicate util.ContainerDevices, device *util.DeviceUsage) bool
ScoreNode(node *corev1.Node, podDevices util.PodSingleDevice, policy string) float32
AddResourceUsage(n *util.DeviceUsage, ctr *util.ContainerDevice) error
// This should not be associated with a specific device object
//ParseConfig(fs *flag.FlagSet)
}
这里定义了一些接口,不同的设备进行不同的实现,在scheduler启动时进行初始化,以供运行中调用
获取到各个节点的各个设备的资源情况之后开始进行打分
3.2.3.2. 根据节点资源信息打分
pkg/scheduler/scheduler.go:458
nodeScores, err := s.calcScore(nodeUsage, nums, annos, args.Pod)
if err != nil {
err := fmt.Errorf("calcScore failed %v for pod %v", err, args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
pkg/scheduler/score.go:198
func (s *Scheduler) calcScore(nodes *map[string]*NodeUsage, nums util.PodDeviceRequests, annos map[string]string, task *corev1.Pod) (*policy.NodeScoreList, error) {
userNodePolicy := config.NodeSchedulerPolicy
if annos != nil {
if value, ok := annos[policy.NodeSchedulerPolicyAnnotationKey]; ok {
userNodePolicy = value
}
}
res := policy.NodeScoreList{
Policy: userNodePolicy,
NodeList: make([]*policy.NodeScore, 0),
}
//func calcScore(nodes *map[string]*NodeUsage, errMap *map[string]string, nums util.PodDeviceRequests, annos map[string]string, task *corev1.Pod) (*NodeScoreList, error) {
// res := make(NodeScoreList, 0, len(*nodes))
for nodeID, node := range *nodes {
viewStatus(*node)
score := policy.NodeScore{NodeID: nodeID, Node: node.Node, Devices: make(util.PodDevices), Score: 0}
score.ComputeDefaultScore(node.Devices)
//This loop is for different container request
ctrfit := false
for ctrid, n := range nums {
sums := 0
for _, k := range n {
sums += int(k.Nums)
}
if sums == 0 {
for idx := range score.Devices {
for len(score.Devices[idx]) <= ctrid {
score.Devices[idx] = append(score.Devices[idx], util.ContainerDevices{})
}
score.Devices[idx][ctrid] = append(score.Devices[idx][ctrid], util.ContainerDevice{})
continue
}
}
klog.V(5).InfoS("fitInDevices", "pod", klog.KObj(task), "node", nodeID)
fit, _ := fitInDevices(node, n, annos, task, &score.Devices)
ctrfit = fit
if !fit {
klog.InfoS("calcScore:node not fit pod", "pod", klog.KObj(task), "node", nodeID)
break
}
}
if ctrfit {
res.NodeList = append(res.NodeList, &score)
score.OverrideScore(node.Devices, userNodePolicy)
}
}
return &res, nil
}
这块逻辑主要分为遍历节点打分,遍历pod的容器计算每个容器对应的设备的分数,返回所有可以承载limits所需资源的node返回
3.2.3.3. 计算出节点的分数
pkg/scheduler/policy/node_policy.go:68
func (ns *NodeScore) ComputeDefaultScore(devices DeviceUsageList) {
used, usedCore, usedMem := int32(0), int32(0), int32(0)
for _, device := range devices.DeviceLists {
used += device.Device.Used
usedCore += device.Device.Usedcores
usedMem += device.Device.Usedmem
}
klog.V(2).Infof("node %s used %d, usedCore %d, usedMem %d,", ns.NodeID, used, usedCore, usedMem)
total, totalCore, totalMem := int32(0), int32(0), int32(0)
for _, deviceLists := range devices.DeviceLists {
total += deviceLists.Device.Count
totalCore += deviceLists.Device.Totalcore
totalMem += deviceLists.Device.Totalmem
}
useScore := float32(used) / float32(total)
coreScore := float32(usedCore) / float32(totalCore)
memScore := float32(usedMem) / float32(totalMem)
ns.Score = float32(Weight) * (useScore + coreScore + memScore)
klog.V(2).Infof("node %s computer default score is %f", ns.NodeID, ns.Score)
}
节点打分规则比较简单
3.2.3.4. 计算每个容器对应的设备的分数
pkg/scheduler/score.go:149
func fitInDevices(node *NodeUsage, requests util.ContainerDeviceRequests, annos map[string]string, pod *corev1.Pod, devinput *util.PodDevices) (bool, float32) {
//devmap := make(map[string]util.ContainerDevices)
devs := util.ContainerDevices{}
total, totalCore, totalMem := int32(0), int32(0), int32(0)
free, freeCore, freeMem := int32(0), int32(0), int32(0)
sums := 0
// computer all device score for one node
for index := range node.Devices.DeviceLists {
node.Devices.DeviceLists[index].ComputeScore(requests)
}
//This loop is for requests for different devices
for _, k := range requests {
sums += int(k.Nums)
if int(k.Nums) > len(node.Devices.DeviceLists) {
klog.InfoS("request devices nums cannot exceed the total number of devices on the node.", "pod", klog.KObj(pod), "request devices nums", k.Nums, "node device nums", len(node.Devices.DeviceLists))
return false, 0
}
sort.Sort(node.Devices)
fit, tmpDevs := fitInCertainDevice(node, k, annos, pod, devinput)
if fit {
for idx, val := range tmpDevs[k.Type] {
for nidx, v := range node.Devices.DeviceLists {
//bc node.Devices has been sorted, so we should find out the correct device
if v.Device.ID != val.UUID {
continue
}
total += v.Device.Count
totalCore += v.Device.Totalcore
totalMem += v.Device.Totalmem
free += v.Device.Count - v.Device.Used
freeCore += v.Device.Totalcore - v.Device.Usedcores
freeMem += v.Device.Totalmem - v.Device.Usedmem
err := device.GetDevices()[k.Type].AddResourceUsage(node.Devices.DeviceLists[nidx].Device, &tmpDevs[k.Type][idx])
if err != nil {
klog.Errorf("AddResource failed:%s", err.Error())
return false, 0
}
klog.Infoln("After AddResourceUsage:", node.Devices.DeviceLists[nidx].Device)
}
}
devs = append(devs, tmpDevs[k.Type]...)
} else {
return false, 0
}
(*devinput)[k.Type] = append((*devinput)[k.Type], devs)
}
return true, 0
}
主要逻辑为
- 给容器对应的每个设备打分、遍历不同的容器对应的limit资源,找到可以承载容器limits资源的设备
pkg/scheduler/policy/gpu_policy.go:58
func (ds *DeviceListsScore) ComputeScore(requests util.ContainerDeviceRequests) {
request, core, mem := int32(0), int32(0), int32(0)
// Here we are required to use the same type device
for _, container := range requests {
request += container.Nums
core += container.Coresreq
if container.MemPercentagereq != 0 && container.MemPercentagereq != 101 {
mem += ds.Device.Totalmem * (container.MemPercentagereq / 100.0)
continue
}
mem += container.Memreq
}
klog.V(2).Infof("device %s user %d, userCore %d, userMem %d,", ds.Device.ID, ds.Device.Used, ds.Device.Usedcores, ds.Device.Usedmem)
usedScore := float32(request+ds.Device.Used) / float32(ds.Device.Count)
coreScore := float32(core+ds.Device.Usedcores) / float32(ds.Device.Totalcore)
memScore := float32(mem+ds.Device.Usedmem) / float32(ds.Device.Totalmem)
ds.Score = float32(Weight) * (usedScore + coreScore + memScore)
klog.V(2).Infof("device %s computer score is %f", ds.Device.ID, ds.Score)
}
打分规则与节点类似
pkg/scheduler/score.go:65
func fitInCertainDevice(node *NodeUsage, request util.ContainerDeviceRequest, annos map[string]string, pod *corev1.Pod, allocated *util.PodDevices) (bool, map[string]util.ContainerDevices) {
k := request
originReq := k.Nums
prevnuma := -1
klog.InfoS("Allocating device for container request", "pod", klog.KObj(pod), "card request", k)
var tmpDevs map[string]util.ContainerDevices
tmpDevs = make(map[string]util.ContainerDevices)
for i := len(node.Devices.DeviceLists) - 1; i >= 0; i-- {
klog.InfoS("scoring pod", "pod", klog.KObj(pod), "Memreq", k.Memreq, "MemPercentagereq", k.MemPercentagereq, "Coresreq", k.Coresreq, "Nums", k.Nums, "device index", i, "device", node.Devices.DeviceLists[i].Device.ID)
found, numa := checkType(annos, *node.Devices.DeviceLists[i].Device, k)
if !found {
klog.InfoS("card type mismatch,continuing...", "pod", klog.KObj(pod), (node.Devices.DeviceLists[i].Device).Type, k.Type)
continue
}
if numa && prevnuma != node.Devices.DeviceLists[i].Device.Numa {
klog.InfoS("Numa not fit, resotoreing", "pod", klog.KObj(pod), "k.nums", k.Nums, "numa", numa, "prevnuma", prevnuma, "device numa", node.Devices.DeviceLists[i].Device.Numa)
k.Nums = originReq
prevnuma = node.Devices.DeviceLists[i].Device.Numa
tmpDevs = make(map[string]util.ContainerDevices)
}
if !checkUUID(annos, *node.Devices.DeviceLists[i].Device, k) {
klog.InfoS("card uuid mismatch,", "pod", klog.KObj(pod), "current device info is:", *node.Devices.DeviceLists[i].Device)
continue
}
memreq := int32(0)
if node.Devices.DeviceLists[i].Device.Count <= node.Devices.DeviceLists[i].Device.Used {
continue
}
if k.Coresreq > 100 {
klog.ErrorS(nil, "core limit can't exceed 100", "pod", klog.KObj(pod))
k.Coresreq = 100
//return false, tmpDevs
}
if k.Memreq > 0 {
memreq = k.Memreq
}
if k.MemPercentagereq != 101 && k.Memreq == 0 {
//This incurs an issue
memreq = node.Devices.DeviceLists[i].Device.Totalmem * k.MemPercentagereq / 100
}
if node.Devices.DeviceLists[i].Device.Totalmem-node.Devices.DeviceLists[i].Device.Usedmem < memreq {
klog.V(5).InfoS("card Insufficient remaining memory", "pod", klog.KObj(pod), "device index", i, "device", node.Devices.DeviceLists[i].Device.ID, "device total memory", node.Devices.DeviceLists[i].Device.Totalmem, "device used memory", node.Devices.DeviceLists[i].Device.Usedmem, "request memory", memreq)
continue
}
if node.Devices.DeviceLists[i].Device.Totalcore-node.Devices.DeviceLists[i].Device.Usedcores < k.Coresreq {
klog.V(5).InfoS("card Insufficient remaining cores", "pod", klog.KObj(pod), "device index", i, "device", node.Devices.DeviceLists[i].Device.ID, "device total core", node.Devices.DeviceLists[i].Device.Totalcore, "device used core", node.Devices.DeviceLists[i].Device.Usedcores, "request cores", k.Coresreq)
continue
}
// Coresreq=100 indicates it want this card exclusively
if node.Devices.DeviceLists[i].Device.Totalcore == 100 && k.Coresreq == 100 && node.Devices.DeviceLists[i].Device.Used > 0 {
klog.V(5).InfoS("the container wants exclusive access to an entire card, but the card is already in use", "pod", klog.KObj(pod), "device index", i, "device", node.Devices.DeviceLists[i].Device.ID, "used", node.Devices.DeviceLists[i].Device.Used)
continue
}
// You can't allocate core=0 job to an already full GPU
if node.Devices.DeviceLists[i].Device.Totalcore != 0 && node.Devices.DeviceLists[i].Device.Usedcores == node.Devices.DeviceLists[i].Device.Totalcore && k.Coresreq == 0 {
klog.V(5).InfoS("can't allocate core=0 job to an already full GPU", "pod", klog.KObj(pod), "device index", i, "device", node.Devices.DeviceLists[i].Device.ID)
continue
}
if !device.GetDevices()[k.Type].CustomFilterRule(allocated, request, tmpDevs[k.Type], node.Devices.DeviceLists[i].Device) {
continue
}
if k.Nums > 0 {
klog.InfoS("first fitted", "pod", klog.KObj(pod), "device", node.Devices.DeviceLists[i].Device.ID)
k.Nums--
tmpDevs[k.Type] = append(tmpDevs[k.Type], util.ContainerDevice{
Idx: int(node.Devices.DeviceLists[i].Device.Index),
UUID: node.Devices.DeviceLists[i].Device.ID,
Type: k.Type,
Usedmem: memreq,
Usedcores: k.Coresreq,
})
}
if k.Nums == 0 {
klog.InfoS("device allocate success", "pod", klog.KObj(pod), "allocate device", tmpDevs)
return true, tmpDevs
}
if node.Devices.DeviceLists[i].Device.Mode == "mig" {
i++
}
}
return false, tmpDevs
}
遍历设备,主要根据设备资源余量来判断是否够container分配,返回所有够分配的设备
pkg/scheduler/scheduler.go:458
nodeScores, err := s.calcScore(nodeUsage, nums, annos, args.Pod)
if err != nil {
err := fmt.Errorf("calcScore failed %v for pod %v", err, args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
return nil, err
}
if len((*nodeScores).NodeList) == 0 {
klog.V(4).Infof("All node scores do not meet for pod %v", args.Pod.Name)
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, fmt.Errorf("no available node, all node scores do not meet"))
return &extenderv1.ExtenderFilterResult{
FailedNodes: failedNodes,
}, nil
}
klog.V(4).Infoln("nodeScores_len=", len((*nodeScores).NodeList))
sort.Sort(nodeScores)
m := (*nodeScores).NodeList[len((*nodeScores).NodeList)-1]
klog.Infof("schedule %v/%v to %v %v", args.Pod.Namespace, args.Pod.Name, m.NodeID, m.Devices)
annotations := make(map[string]string)
annotations[util.AssignedNodeAnnotations] = m.NodeID
annotations[util.AssignedTimeAnnotations] = strconv.FormatInt(time.Now().Unix(), 10)
for _, val := range device.GetDevices() {
val.PatchAnnotations(&annotations, m.Devices)
}
//InRequestDevices := util.EncodePodDevices(util.InRequestDevices, m.devices)
//supportDevices := util.EncodePodDevices(util.SupportDevices, m.devices)
//maps.Copy(annotations, InRequestDevices)
//maps.Copy(annotations, supportDevices)
s.addPod(args.Pod, m.NodeID, m.Devices)
err = util.PatchPodAnnotations(args.Pod, annotations)
if err != nil {
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringFailed, []string{}, err)
s.delPod(args.Pod)
return nil, err
}
s.recordScheduleFilterResultEvent(args.Pod, EventReasonFilteringSucceed, []string{m.NodeID}, nil)
res := extenderv1.ExtenderFilterResult{NodeNames: &[]string{m.NodeID}}
return &res, nil
遍历完成之后选择分数最高的, 给pod打标签
apiVersion: v1
kind: Pod
metadata:
annotations:
hami.io/vgpu-node: node1
hami.io/vgpu-time: "1733988480"
hami.io/vgpu-devices-allocated: GPU-7aebc545-cbd3-18a0-afce-76cae449702a,NVIDIA,20000,80:;
hami.io/vgpu-devices-to-allocate: ;
3.2.4. binding实现
bind逻辑比较简单,将pod绑定到node
pkg/scheduler/routes/route.go:82
func Bind(s *scheduler.Scheduler) httprouter.Handle {
return func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
var buf bytes.Buffer
body := io.TeeReader(r.Body, &buf)
var extenderBindingArgs extenderv1.ExtenderBindingArgs
var extenderBindingResult *extenderv1.ExtenderBindingResult
if err := json.NewDecoder(body).Decode(&extenderBindingArgs); err != nil {
klog.ErrorS(err, "Decode extender binding args")
extenderBindingResult = &extenderv1.ExtenderBindingResult{
Error: err.Error(),
}
} else {
extenderBindingResult, err = s.Bind(extenderBindingArgs)
}
if response, err := json.Marshal(extenderBindingResult); err != nil {
klog.ErrorS(err, "Marshal binding result", "result", extenderBindingResult)
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusInternalServerError)
errMsg := fmt.Sprintf("{'error':'%s'}", err.Error())
w.Write([]byte(errMsg))
} else {
klog.V(5).InfoS("Return bind response", "result", extenderBindingResult)
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusOK)
w.Write(response)
}
}
}
路由处理
``
func (s *Scheduler) Bind(args extenderv1.ExtenderBindingArgs) (*extenderv1.ExtenderBindingResult, error) {
klog.InfoS("Bind", "pod", args.PodName, "namespace", args.PodNamespace, "podUID", args.PodUID, "node", args.Node)
var err error
var res *extenderv1.ExtenderBindingResult
binding := &corev1.Binding{
ObjectMeta: metav1.ObjectMeta{Name: args.PodName, UID: args.PodUID},
Target: corev1.ObjectReference{Kind: "Node", Name: args.Node},
}
current, err := s.kubeClient.CoreV1().Pods(args.PodNamespace).Get(context.Background(), args.PodName, metav1.GetOptions{})
if err != nil {
klog.ErrorS(err, "Get pod failed")
}
node, err := s.kubeClient.CoreV1().Nodes().Get(context.Background(), args.Node, metav1.GetOptions{})
if err != nil {
klog.ErrorS(err, "Failed to get node", "node", args.Node)
s.recordScheduleBindingResultEvent(current, EventReasonBindingFailed, []string{}, fmt.Errorf("failed to get node %v", args.Node))
res = &extenderv1.ExtenderBindingResult{
Error: err.Error(),
}
return res, nil
}
tmppatch := make(map[string]string)
for _, val := range device.GetDevices() {
err = val.LockNode(node, current)
if err != nil {
goto ReleaseNodeLocks
}
}
tmppatch[util.DeviceBindPhase] = "allocating"
tmppatch[util.BindTimeAnnotations] = strconv.FormatInt(time.Now().Unix(), 10)
err = util.PatchPodAnnotations(current, tmppatch)
if err != nil {
klog.ErrorS(err, "patch pod annotation failed")
}
if err = s.kubeClient.CoreV1().Pods(args.PodNamespace).Bind(context.Background(), binding, metav1.CreateOptions{}); err != nil {
klog.ErrorS(err, "Failed to bind pod", "pod", args.PodName, "namespace", args.PodNamespace, "podUID", args.PodUID, "node", args.Node)
}
if err == nil {
s.recordScheduleBindingResultEvent(current, EventReasonBindingSucceed, []string{args.Node}, nil)
res = &extenderv1.ExtenderBindingResult{
Error: "",
}
klog.Infoln("After Binding Process")
return res, nil
}
ReleaseNodeLocks:
klog.InfoS("bind failed", "err", err.Error())
for _, val := range device.GetDevices() {
val.ReleaseNodeLock(node, current)
}
s.recordScheduleBindingResultEvent(current, EventReasonBindingFailed, []string{}, err)
return &extenderv1.ExtenderBindingResult{
Error: err.Error(),
}, nil
}
3.3. Node将设备情况写入node annotation
scheduler获取node的设备信息主要是通过读取node的annotation,主要有如下几步
- 启动插件
apiVersion: v1
kind: Node
metadata:
annotations:
hami.io/node-handshake: Requesting_2024.12.24 03:31:30
hami.io/node-handshake-dcu: Deleted_2024.12.06 07:43:49
hami.io/node-nvidia-register: 'GPU-7aebc545-cbd3-18a0-afce-76cae449702a,10,73728,300,NVIDIA-NVIDIA
GeForce RTX 3090,0,true:'
3.3.1. 启动device-plugin服务
这里用到了 github.com/urfave/cli/v2 作为command启动服务,需要注意 -v不是日志等级而是是否显示版本
cmd/device-plugin/nvidia/main.go:40
func main() {
var configFile string
c := cli.NewApp()
c.Name = "NVIDIA Device Plugin"
c.Usage = "NVIDIA device plugin for Kubernetes"
c.Version = info.GetVersionString()
c.Action = func(ctx *cli.Context) error {
return start(ctx, c.Flags)
}
3.3.2. 启动plugin
这里的plugin主要是针对不同厂家的设备需要实现不同的方法,这里定义了pluigin的控制器,例如start、restart、exit等,这里我们主要关注plugins, restartPlugins, err := startPlugins(c, flags, restarting)
cmd/device-plugin/nvidia/main.go:156
func start(c *cli.Context, flags []cli.Flag) error {
klog.Info("Starting FS watcher.")
util.NodeName = os.Getenv(util.NodeNameEnvName)
watcher, err := newFSWatcher(kubeletdevicepluginv1beta1.DevicePluginPath)
if err != nil {
return fmt.Errorf("failed to create FS watcher: %v", err)
}
defer watcher.Close()
//device.InitDevices()
/*Loading config files*/
klog.Infof("Start working on node %s", util.NodeName)
klog.Info("Starting OS watcher.")
sigs := newOSWatcher(syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
var restarting bool
var restartTimeout <-chan time.Time
var plugins []plugin.Interface
restart:
// If we are restarting, stop plugins from previous run.
if restarting {
err := stopPlugins(plugins)
if err != nil {
return fmt.Errorf("error stopping plugins from previous run: %v", err)
}
}
klog.Info("Starting Plugins.")
plugins, restartPlugins, err := startPlugins(c, flags, restarting)
if err != nil {
return fmt.Errorf("error starting plugins: %v", err)
}
if restartPlugins {
klog.Info("Failed to start one or more plugins. Retrying in 30s...")
restartTimeout = time.After(30 * time.Second)
}
restarting = true
// Start an infinite loop, waiting for several indicators to either log
// some messages, trigger a restart of the plugins, or exit the program.
for {
select {
// If the restart timeout has expired, then restart the plugins
case <-restartTimeout:
goto restart
// Detect a kubelet restart by watching for a newly created
// 'kubeletdevicepluginv1beta1.KubeletSocket' file. When this occurs, restart this loop,
// restarting all of the plugins in the process.
case event := <-watcher.Events:
if event.Name == kubeletdevicepluginv1beta1.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
klog.Infof("inotify: %s created, restarting.", kubeletdevicepluginv1beta1.KubeletSocket)
goto restart
}
// Watch for any other fs errors and log them.
case err := <-watcher.Errors:
klog.Errorf("inotify: %s", err)
// Watch for any signals from the OS. On SIGHUP, restart this loop,
// restarting all of the plugins in the process. On all other
// signals, exit the loop and exit the program.
case s := <-sigs:
switch s {
case syscall.SIGHUP:
klog.Info("Received SIGHUP, restarting.")
goto restart
default:
klog.Infof("Received signal \"%v\", shutting down.", s)
goto exit
}
}
}
exit:
err = stopPlugins(plugins)
if err != nil {
return fmt.Errorf("error stopping plugins: %v", err)
}
return nil
}
cmd/device-plugin/nvidia/main.go:239
启动插件,主要方法 p.Start()
func startPlugins(c *cli.Context, flags []cli.Flag, restarting bool) ([]plugin.Interface, bool, error) {
// Load the configuration file
klog.Info("Loading configuration.")
config, err := loadConfig(c, flags)
if err != nil {
return nil, false, fmt.Errorf("unable to load config: %v", err)
}
disableResourceRenamingInConfig(config)
/*Loading config files*/
//fmt.Println("NodeName=", config.NodeName)
devConfig, err := generateDeviceConfigFromNvidia(config, c, flags)
if err != nil {
klog.Errorf("failed to load config file %s", err.Error())
return nil, false, err
}
// Update the configuration file with default resources.
klog.Info("Updating config with default resource matching patterns.")
err = rm.AddDefaultResourcesToConfig(&devConfig)
if err != nil {
return nil, false, fmt.Errorf("unable to add default resources to config: %v", err)
}
// Print the config to the output.
configJSON, err := json.MarshalIndent(devConfig, "", " ")
if err != nil {
return nil, false, fmt.Errorf("failed to marshal config to JSON: %v", err)
}
klog.Infof("\nRunning with config:\n%v", string(configJSON))
// Get the set of plugins.
klog.Info("Retrieving plugins.")
pluginManager, err := NewPluginManager(&devConfig)
if err != nil {
return nil, false, fmt.Errorf("error creating plugin manager: %v", err)
}
plugins, err := pluginManager.GetPlugins()
if err != nil {
return nil, false, fmt.Errorf("error getting plugins: %v", err)
}
// Loop through all plugins, starting them if they have any devices
// to serve. If even one plugin fails to start properly, try
// starting them all again.
started := 0
for _, p := range plugins {
// Just continue if there are no devices to serve for plugin p.
if len(p.Devices()) == 0 {
continue
}
// Start the gRPC server for plugin p and connect it with the kubelet.
if err := p.Start(); err != nil {
klog.Error("Could not contact Kubelet. Did you enable the device plugin feature gate?")
klog.Error("You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites")
klog.Error("You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start")
return plugins, true, nil
}
started++
}
if started == 0 {
klog.Info("No devices found. Waiting indefinitely.")
}
return plugins, false, nil
}
其中p(plugin)需要实现几个方法来管理插件
pkg/device-plugin/nvidiadevice/nvinternal/plugin/api.go:37
type Interface interface {
Devices() rm.Devices
Start() error
Stop() error
}
同时如果需要kubelet能够识别 resource中的类似 nvidia.com/gpu: 1 这样的拓展字段需要启动一个grpc服务挂载 /var/lib/kubelet/device-plugins/ 且实现如下方法, 这块跟调度相关性不大,暂且不展开 device-plugins
k8s.io/kubelet@v0.28.3/pkg/apis/deviceplugin/v1beta1/api.pb.go:1419
type DevicePluginServer interface {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
GetDevicePluginOptions(context.Context, *Empty) (*DevicePluginOptions, error)
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
ListAndWatch(*Empty, DevicePlugin_ListAndWatchServer) error
// GetPreferredAllocation returns a preferred set of devices to allocate
// from a list of available ones. The resulting preferred allocation is not
// guaranteed to be the allocation ultimately performed by the
// devicemanager. It is only designed to help the devicemanager make a more
// informed allocation decision when possible.
GetPreferredAllocation(context.Context, *PreferredAllocationRequest) (*PreferredAllocationResponse, error)
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
Allocate(context.Context, *AllocateRequest) (*AllocateResponse, error)
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as resetting the device before making devices available to the container
PreStartContainer(context.Context, *PreStartContainerRequest) (*PreStartContainerResponse, error)
}
3.3.3. nvidia插件的实现
主要看plugin.WatchAndRegister()
pkg/device-plugin/nvidiadevice/nvinternal/plugin/server.go:196
func (plugin *NvidiaDevicePlugin) Start() error {
plugin.initialize()
err := plugin.Serve()
if err != nil {
klog.Infof("Could not start device plugin for '%s': %s", plugin.rm.Resource(), err)
plugin.cleanup()
return err
}
klog.Infof("Starting to serve '%s' on %s", plugin.rm.Resource(), plugin.socket)
err = plugin.Register()
if err != nil {
klog.Infof("Could not register device plugin: %s", err)
plugin.Stop()
return err
}
klog.Infof("Registered device plugin for '%s' with Kubelet", plugin.rm.Resource())
if plugin.operatingMode == "mig" {
cmd := exec.Command("nvidia-mig-parted", "export")
var stdout, stderr bytes.Buffer
cmd.Stdout = &stdout
cmd.Stderr = &stderr
err := cmd.Run()
if err != nil {
klog.Fatalf("nvidia-mig-parted failed with %s\n", err)
}
outStr := stdout.Bytes()
yaml.Unmarshal(outStr, &plugin.migCurrent)
os.WriteFile("/tmp/migconfig.yaml", outStr, os.ModePerm)
if len(plugin.migCurrent.MigConfigs["current"]) == 1 && len(plugin.migCurrent.MigConfigs["current"][0].Devices) == 0 {
idx := 0
plugin.migCurrent.MigConfigs["current"][0].Devices = make([]int32, 0)
for idx < GetDeviceNums() {
plugin.migCurrent.MigConfigs["current"][0].Devices = append(plugin.migCurrent.MigConfigs["current"][0].Devices, int32(idx))
idx++
}
}
klog.Infoln("Mig export", plugin.migCurrent)
}
go func() {
err := plugin.rm.CheckHealth(plugin.stop, plugin.health)
if err != nil {
klog.Infof("Failed to start health check: %v; continuing with health checks disabled", err)
}
}()
go func() {
plugin.WatchAndRegister()
}()
return nil
}
这里是个定时器,每30s收集一次该node的设备信息,并写入node annotation
func (plugin *NvidiaDevicePlugin) WatchAndRegister() {
klog.Info("Starting WatchAndRegister")
errorSleepInterval := time.Second * 5
successSleepInterval := time.Second * 30
for {
err := plugin.RegistrInAnnotation()
if err != nil {
klog.Errorf("Failed to register annotation: %v", err)
klog.Infof("Retrying in %v seconds...", errorSleepInterval)
time.Sleep(errorSleepInterval)
} else {
klog.Infof("Successfully registered annotation. Next check in %v seconds...", successSleepInterval)
time.Sleep(successSleepInterval)
}
}
}
func (plugin *NvidiaDevicePlugin) RegistrInAnnotation() error {
devices := plugin.getAPIDevices()
klog.InfoS("start working on the devices", "devices", devices)
annos := make(map[string]string)
node, err := util.GetNode(util.NodeName)
if err != nil {
klog.Errorln("get node error", err.Error())
return err
}
encodeddevices := util.EncodeNodeDevices(*devices)
annos[nvidia.HandshakeAnnos] = "Reported " + time.Now().String()
annos[nvidia.RegisterAnnos] = encodeddevices
klog.Infof("patch node with the following annos %v", fmt.Sprintf("%v", annos))
err = util.PatchNodeAnnotations(node, annos)
if err != nil {
klog.Errorln("patch node error", err.Error())
}
return err
}
具体数据收集逻辑
pkg/device-plugin/nvidiadevice/nvinternal/plugin/register.go:110
func (plugin *NvidiaDevicePlugin) getAPIDevices() *[]*util.DeviceInfo {
devs := plugin.Devices()
klog.V(5).InfoS("getAPIDevices", "devices", devs)
nvml.Init()
res := make([]*util.DeviceInfo, 0, len(devs))
for UUID := range devs {
ndev, ret := nvml.DeviceGetHandleByUUID(UUID)
if ret != nvml.SUCCESS {
klog.Errorln("nvml new device by index error uuid=", UUID, "err=", ret)
panic(0)
}
idx, ret := ndev.GetIndex()
if ret != nvml.SUCCESS {
klog.Errorln("nvml get index error ret=", ret)
panic(0)
}
memoryTotal := 0
memory, ret := ndev.GetMemoryInfo()
if ret == nvml.SUCCESS {
memoryTotal = int(memory.Total)
} else {
klog.Error("nvml get memory error ret=", ret)
panic(0)
}
Model, ret := ndev.GetName()
if ret != nvml.SUCCESS {
klog.Error("nvml get name error ret=", ret)
panic(0)
}
registeredmem := int32(memoryTotal / 1024 / 1024)
if plugin.schedulerConfig.DeviceMemoryScaling != 1 {
registeredmem = int32(float64(registeredmem) * plugin.schedulerConfig.DeviceMemoryScaling)
}
klog.Infoln("MemoryScaling=", plugin.schedulerConfig.DeviceMemoryScaling, "registeredmem=", registeredmem)
health := true
for _, val := range devs {
if strings.Compare(val.ID, UUID) == 0 {
// when NVIDIA-Tesla P4, the device info is : ID:GPU-e290caca-2f0c-9582-acab-67a142b61ffa,Health:Healthy,Topology:nil,
// it is more reasonable to think of healthy as case-insensitive
if strings.EqualFold(val.Health, "healthy") {
health = true
} else {
health = false
}
break
}
}
numa, err := plugin.getNumaInformation(idx)
if err != nil {
klog.ErrorS(err, "failed to get numa information", "idx", idx)
}
res = append(res, &util.DeviceInfo{
ID: UUID,
Index: uint(idx),
Count: int32(plugin.schedulerConfig.DeviceSplitCount),
Devmem: registeredmem,
Devcore: int32(plugin.schedulerConfig.DeviceCoreScaling * 100),
Type: fmt.Sprintf("%v-%v", "NVIDIA", Model),
Numa: numa,
Mode: plugin.operatingMode,
Health: health,
})
klog.Infof("nvml registered device id=%v, memory=%v, type=%v, numa=%v", idx, registeredmem, Model, numa)
}
return &res
}
这里通过nvidia驱动获取设备信息,需要注意的是这里有配置DeviceMemoryScaling, 内存超分配置,这里是通过命令行启动的–config-file 参数指定的schduler配置和代码中固化的config/config.json 来取值的,其中config/config.json 优先级大于–config-file
到这里,调度所需的所有东西就准备好了,pod可以顺利被分配到合适的节点上