vLLM:高性能大语言模型推理框架源码解析与最佳实践
目录
- 引言
- 快速上手
2.1. 安装配置
2.2. 基本用法 - 核心调用流程分析
3.1. 总体调用链路概述
3.2. 核心组件与类层次结构
3.3. 初始化阶段详细流程
3.4. 推理阶段详细流程
3.5. 完整调用链路示例
3.6. 关键调用路径总结 - vLLM 关键工作机制
4.1. PagedAttention 机制
4.2. 连续批处理技术
4.3. CUDA 图捕获与加速
4.4. KV 缓存管理
4.5. 内存优化策略
4.6. 并行计算优化 - 架构与类关系图
5.1. 整体架构概览
5.2. 核心类结构图
5.3. 关键组件交互流程
5.4. 并行与分布式架构
5.5. 内存管理架构 - 高级 Python 语法应用
6.1. 类型注解与泛型编程
6.2. 动态类解析与反射机制
6.3. 方法委托与魔术方法
6.4. 弱引用与特殊调用模式
6.5. 类方法与工厂模式
6.6. 装饰器高级应用
6.7. 上下文管理与多重上下文 - 性能优化与最佳实践
7.1. 示例应用:构建高性能API服务
7.2. 性能优化策略
7.3. 部署最佳实践
7.4. 常见问题与解决方案 - 总结与展望
8.1. 技术创新点总结
8.2. 与其他框架对比
8.3. 未来发展趋势
8.4. 实践建议
附录
1. 引言
vLLM 是一个高性能的大语言模型推理框架,通过创新的 PagedAttention 机制和优化的内存管理,实现了高吞吐量和低延迟的文本生成服务。本文将深入分析 vLLM 的源码,重点关注其调用流程、高级 Python 语法应用以及核心工作机制,帮助读者更好地理解和使用这一强大工具。
2. 快速上手
2.1 安装配置
vLLM 支持多种硬件平台,安装方式也略有不同:
# 基本安装(CUDA 支持)
pip install vllm
# 从源码安装
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e .
2.2 基本用法
下面是一个简单的 vLLM 使用示例,展示了如何加载模型并生成文本:
# 导入必要的库
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(model="/opt/data/models/Llama-3.2-1B-Instruct")
# 设置生成参数
sampling_params = SamplingParams(
max_tokens=100, # 最大生成长度
temperature=0.7, # 控制随机性
top_p=0.9, # 控制取样范围
stop=["</s>", "\n\n"] # 停止标记
)
# 准备输入提示
prompts = [
"介绍一下北京的旅游景点",
"写一首关于春天的诗",
]
# 生成文本
outputs = llm.generate(prompts, sampling_params)
# 打印结果
for output in outputs:
print(f"Prompt: {output.prompt}")
print(f"Generated: {output.outputs[0].text}")
print("-" * 50)
3. 核心调用流程分析
3.1 总体调用链路概述
vLLM 框架的调用流程可以分为初始化阶段和推理阶段两个主要部分。整个流程涉及多个核心组件的协同工作,包括 LLM Engine、Worker、Scheduler、ModelRunner 等类。以下是端到端完整调用链路的详细分析:
用户 API 调用
↓
LLMEngine 初始化
↓
模型加载与配置初始化
↓
Worker 池初始化
↓
请求处理与调度
↓
Tokenizer 处理输入
↓
ModelRunner 执行推理
↓
KV 缓存管理
↓
结果获取与后处理
↓
返回生成结果
3.2 核心组件与类层次结构
vLLM 的架构由以下核心组件组成:
- LLMEngine:整个框架的中枢,负责协调各组件工作
- Worker:实际执行模型计算的组件
- ModelRunner:负责模型的前向传播计算
- Scheduler:请求调度器,决定何时处理哪些请求
- SamplingParams:控制文本生成的参数
- Request/Response:请求和响应的数据结构
- SequenceGroup/Sequence:表示生成序列的数据结构
- BlockManager:管理 KV 缓存的物理块
- Tokenizer:负责文本标记化
类层次结构图:
LLMEngine
├── AsyncEngineDeadlockMonitor
├── ModelConfig
├── DeviceConfig
├── ParallelConfig
├── Scheduler
│ ├── SchedulerConfig
│ └── SchedulingStrategy
├── RequestTracker
└── WorkerPool
├── Worker
│ ├── ModelRunner
│ │ ├── CUDAGraph
│ │ └── AttentionState
│ └── BlockSpaceManager
│ └── BlockAllocator
└── ModelReplica
3.3 初始化阶段详细流程
3.3.1 LLMEngine 初始化
LLMEngine 是整个 vLLM 的核心,负责协调各组件工作。它的初始化流程如下:
def __init__(
self,
model_config: ModelConfig,
scheduler_config: SchedulerConfig,
device_config: Optional[DeviceConfig] = None,
parallel_config: Optional[ParallelConfig] = None,
**kwargs,
) -> None:
# 1. 设置基本配置
self.model_config = model_config
self.scheduler_config = scheduler_config
if device_config is None:
device_config = DeviceConfig()
self.device_config = device_config
if parallel_config is None:
parallel_config = ParallelConfig()
self.parallel_config = parallel_config
# 2. 初始化策略配置
self.num_nodes = parallel_config.world_size // parallel_config.tensor_parallel_size
self.distributed_init_method = kwargs.get("distributed_init_method", None)
self.max_logprobs = kwargs.get("max_logprobs", None)
# 3. 初始化组件
self.tokenizer = self._init_tokenizer()
self.schedulers = self._init_schedulers()
self.request_tracker = RequestTracker()
# 4. 初始化 Worker 池
self.worker_pool = WorkerPool(
model_config=model_config,
parallel_config=parallel_config,
scheduler_config=scheduler_config,
device_config=device_config,
local_rank=parallel_config.local_rank,
)
# 5. 启动引擎线程
self._start_background_thread()
初始化过程中的配置详解:
- ModelConfig:包含模型相关的配置,如模型路径、类型、量化设置等
class ModelConfig: def __init__( self, model: str, tokenizer: Optional[str] = None, tokenizer_mode: str = "auto", trust_remote_code: bool = False, dtype: str = "auto", quantization: Optional[str] = None, revision: Optional[str] = None, code_revision: Optional[str] = None, tokenizer_revision: Optional[str] = None, # ... 更多参数 ) -> None: # 初始化模型配置 - DeviceConfig:包含设备相关配置,如GPU数量、每个GPU的最大内存等
class DeviceConfig: def __init__( self, device_type: Optional[str] = None, max_memory_per_gpu: Optional[Dict[int, str]] = None, # ... 更多参数 ) -> None: # 初始化设备配置 - ParallelConfig:包含并行计算相关配置,如张量并行度、流水线并行度等
class ParallelConfig: def __init__( self, tensor_parallel_size: int = 1, pipeline_parallel_size: int = 1, # ... 更多参数 ) -> None: # 初始化并行配置
3.3.2 Tokenizer 初始化
Tokenizer 负责将输入文本转换为模型可以处理的 token ID 序列:
def _init_tokenizer(self) -> PreTrainedTokenizer:
"""初始化 tokenizer"""
# 加载 tokenizer
tokenizer = get_tokenizer(
model_name=self.model_config.model,
tokenizer_name=self.model_config.tokenizer,
tokenizer_mode=self.model_config.tokenizer_mode,
trust_remote_code=self.model_config.trust_remote_code,
revision=self.model_config.tokenizer_revision,
)
# 配置特殊 token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 检查并处理特殊 token ID
if (self.model_config.chat_template is not None and
self.model_config.chat_template != "none"):
tokenizer.chat_template = self.model_config.chat_template
return tokenizer
3.3.3 Scheduler 初始化
Scheduler 负责调度请求,决定哪些请求应该被处理以及何时处理:
def _init_schedulers(self) -> List[Scheduler]:
"""初始化调度器"""
# 创建多个调度器实例,每个对应一个模型副本
schedulers = []
for rank in range(self.num_nodes):
# 创建调度器实例
scheduler = Scheduler(
# 配置调度器
scheduler_config=self.scheduler_config,
max_num_batched_tokens=self.worker_pool.max_num_batched_tokens,
max_num_seqs=self.worker_pool.max_num_seqs,
device=f"cuda:{self.parallel_config.local_rank}" if torch.cuda.is_available() else "cpu",
)
schedulers.append(scheduler)
return schedulers
3.3.4 Worker 池初始化
Worker 池负责管理多个 Worker 实例,处理并发请求:
class WorkerPool:
def __init__(
self,
model_config: ModelConfig,
parallel_config: ParallelConfig,
scheduler_config: SchedulerConfig,
device_config: DeviceConfig,
local_rank: int,
) -> None:
# 1. 设置基本配置
self.model_config = model_config
self.parallel_config = parallel_config
self.scheduler_config = scheduler_config
self.device_config = device_config
self.local_rank = local_rank
# 2. 初始化其他参数
self.max_num_seqs = scheduler_config.max_num_seqs
self.max_num_batched_tokens = scheduler_config.max_num_batched_tokens
# 3. 初始化 Worker
self.workers: List[Worker] = []
self.model_replicas = []
# 4. 加载模型并创建 Worker
self._initialize_workers()
Worker 初始化时会加载模型并准备执行环境:
def _initialize_workers(self) -> None:
"""初始化 Worker"""
# 创建模型副本
self.model_replicas = self._initialize_model_replicas()
# 为每个模型副本创建一个 Worker
for i, model_replica in enumerate(self.model_replicas):
worker = Worker(
model_config=self.model_config,
model_replica=model_replica,
# ... 其他参数
)
self.workers.append(worker)
3.4 推理阶段详细流程
3.4.1 请求接收与处理
用户通过 API 发送请求,LLMEngine 接收并处理请求:
def add_request(
self,
request_id: str,
prompt: Optional[str],
sampling_params: SamplingParams,
prompt_token_ids: Optional[List[int]] = None,
arrival_time: Optional[float] = None,
) -> Optional[int]:
"""添加一个新请求"""
# 1. 记录请求到达时间
if arrival_time is None:
arrival_time = time.time()
# 2. 处理输入
if prompt is None and prompt_token_ids is None:
raise ValueError("Either prompt or prompt_token_ids must be provided")
# 3. 如果需要,使用 tokenizer 处理输入文本
if prompt_token_ids is None:
assert prompt is not None
prompt_token_ids = self.tokenizer.encode(prompt)
# 4. 创建请求并添加到队列
request = Request(
request_id=request_id,
prompt=prompt,
prompt_token_ids=prompt_token_ids,
sampling_params=sampling_params,
arrival_time=arrival_time,
)
# 5. 将请求添加到请求跟踪器
self.request_tracker.add_request(request)
# 6. 将请求添加到调度器
self.schedulers[0].add_request(request)
return len(prompt_token_ids)
3.4.2 请求调度
Scheduler 负责决定何时处理哪些请求:
def schedule(self) -> List[SequenceGroupMetadata]:
"""调度请求执行"""
# 1. 获取系统状态
now = time.time()
# 2. 从等待队列和运行中队列选择可处理的序列组
seq_groups = self._get_schedulable_groups()
# 3. 根据调度策略对序列组排序
seq_groups = self._sort_by_strategy(seq_groups)
# 4. 根据资源约束选择可处理的序列组
scheduled_groups = self._select_best_fitting_groups(seq_groups)
# 5. 生成调度元数据
metadata = self._create_schedule_metadata(scheduled_groups)
return metadata
3.4.3 模型执行
ModelRunner 负责执行模型的前向传播:
def execute_model(
self,
input_ids: torch.Tensor,
positions: torch.Tensor,
kv_caches: List[torch.Tensor],
block_tables: torch.Tensor,
) -> Tuple[torch.Tensor, List[torch.Tensor]]:
"""执行模型前向传播"""
# 1. 准备输入
batch_size = input_ids.shape[0]
# 2. 如果已启用 CUDA 图捕获并且批大小匹配,使用 CUDA 图执行
if (self.model_captured and batch_size in self.graph_runners and
not self.disable_graphs):
# 使用预先捕获的 CUDA 图执行模型
return self._execute_with_graph(batch_size, input_ids, positions,
kv_caches, block_tables)
else:
# 使用标准方式执行模型
return self._forward_helper(input_ids, positions, kv_caches,
block_tables)
3.4.4 KV 缓存管理
BlockManager 负责管理 KV 缓存的物理块:
def allocate(self, seq_id: int, num_tokens: int) -> List[int]:
"""为序列分配 KV 缓存块"""
# 1. 计算需要的块数
num_blocks = (num_tokens + self.block_size - 1) // self.block_size
# 2. 分配物理块
block_indices = []
for _ in range(num_blocks):
block_idx = self.block_allocator.allocate()
block_indices.append(block_idx)
# 3. 更新映射表
self.block_tables[seq_id] = block_indices
return block_indices
3.4.5 结果处理与返回
LLMEngine 处理模型输出并返回生成结果:
def _process_model_outputs(
self,
seq_group: SequenceGroup,
outputs: ModelOutput,
metadata: SequenceGroupMetadata,
) -> None:
"""处理模型输出"""
# 1. 处理 logits 和采样结果
logprobs = outputs.logprobs
next_tokens = outputs.next_tokens
# 2. 为每个序列更新状态
for seq_id, seq in seq_group.seqs.items():
# 获取对应的 token 和概率
next_token = next_tokens[seq_id]
logprob = logprobs[seq_id] if logprobs is not None else None
# 更新序列状态
seq.append_token_id(next_token, logprob)
# 检查是否达到终止条件
if self._is_finished(seq, next_token):
seq.status = SequenceStatus.FINISHED
3.5 完整调用链路示例
以下是从用户请求到生成文本的完整调用链路示例:
- 用户 API 调用:
from vllm import LLM, SamplingParams # 设置采样参数 sampling_params = SamplingParams( temperature=0.8, top_p=0.95, max_tokens=100 ) # 初始化 LLM llm = LLM(model="gpt-3.5-turbo") # 发送请求 outputs = llm.generate("Tell me a joke", sampling_params=sampling_params) # 获取结果 print(outputs[0].outputs[0].text) - LLM 初始化:
# LLM 类内部初始化 LLMEngine self.engine = LLMEngine( model=model, tokenizer=tokenizer, # 其他参数... ) - 请求处理:
# LLM.generate 方法内部调用 LLMEngine.add_request request_id = self.engine.add_request( prompt=prompt, sampling_params=sampling_params ) - 请求调度与执行:
# LLMEngine 内部的调度循环 while not engine_stopped: # 1. 调度请求 scheduled_groups = self.scheduler.schedule() # 2. 将调度的请求发送给 Worker for worker, metadata in zip(self.workers, scheduled_groups): worker.execute_model(metadata) # 3. 处理模型输出 for output in outputs: self._process_model_outputs(output) # 4. 更新请求状态 self.request_tracker.update_status() - 结果返回:
# LLMEngine 将结果返回给 LLM finished_requests = self.request_tracker.get_finished() # LLM 将结果返回给用户 return [r.get_result() for r in finished_requests]
3.6 关键调用路径总结
vLLM 的核心调用流程可以总结为以下几个关键路径:
- 初始化路径:
LLM.__init__ → LLMEngine.__init__ → [ModelConfig, DeviceConfig, ParallelConfig 初始化] → Tokenizer 初始化 → Worker 池初始化 → [模型加载, Scheduler 初始化] → 引擎线程启动 - 请求处理路径:
LLM.generate → LLMEngine.add_request → Tokenizer.encode → RequestTracker.add_request → Scheduler.add_request → Scheduler.schedule → Worker.execute_model → ModelRunner.forward → [BlockManager 管理 KV 缓存] → LLMEngine._process_model_outputs → LLM 返回结果 - 并行执行路径:
多个 Worker 并行执行 → 每个 Worker 内部使用 CUDA 图加速 → 使用张量并行和流水线并行提高吞吐量
通过这种模块化的设计,vLLM 能够高效地处理大量并发请求,同时优化内存使用和计算资源分配,为大型语言模型提供高性能的推理服务。
4. vLLM 关键工作机制
vLLM 的高性能源于几项关键技术创新。这些机制共同解决了大语言模型推理中的主要瓶颈问题:内存效率、计算速度和资源利用率。以下是这些核心机制的详细分析,即使没有深厚的技术背景,也能理解它们解决的问题和带来的好处。
5.1 PagedAttention 机制
PagedAttention 是 vLLM 的核心创新,通过分页管理 KV 缓存提高内存效率。这一机制受操作系统中的虚拟内存管理启发,解决了大语言模型推理中的关键瓶颈问题。
KV 缓存的挑战
在标准的 Transformer 解码器中,每生成一个新 token,都需要计算注意力,这涉及与之前所有 token 的 key 和 value 的交互。随着序列长度增加,这些 key 和 value 缓存(即 KV 缓存)占用的内存也线性增长:
# 传统 KV 缓存的内存占用
memory_per_seq = seq_len * num_layers * 2 * hidden_dim * dtype_size
对于长序列和批处理请求,内存消耗非常显著。例如,一个批次中有多个不同长度的序列,传统方法需要为每个序列分配足够大的连续内存块,导致内存碎片和浪费。
PagedAttention 原理
PagedAttention 的核心思想是将 KV 缓存组织成固定大小的物理块,并使用块表映射逻辑位置到物理块:
class PagedAttention:
def __init__(self, block_size: int):
self.block_size = block_size
self.block_tables = {} # 序列到物理块的映射
self.physical_blocks = [] # 实际存储块
def allocate_block(self, seq_id: int):
"""为序列分配新块"""
if seq_id not in self.block_tables:
self.block_tables[seq_id] = []
# 分配新物理块
block_id = self._find_free_block()
self.block_tables[seq_id].append(block_id)
def get_kv_cache(self, seq_id: int, positions: torch.Tensor):
"""获取缓存内容"""
if seq_id not in self.block_tables:
return None
# 计算物理块索引和块内位置
block_indices, block_offsets = self._compute_indices(positions)
physical_blocks = [self.block_tables[seq_id][idx] for idx in block_indices]
# 获取缓存内容
return self._gather_blocks(physical_blocks, block_offsets)
工作流程:
- 内存分块:KV 缓存被划分为固定大小的块(如每块 16 个 token)
- 动态分配:每个序列动态分配所需的块,而不是预先分配
- 虚拟寻址:使用块表将逻辑位置映射到物理块
- 资源复用:当序列完成时,其块可以被释放并重用
技术细节
实际实现中,PagedAttention 包含以下关键组件:
- BlockAllocator:管理物理块的分配和释放
class BlockAllocator:
def __init__(self, num_blocks: int):
self.num_blocks = num_blocks
self.free_blocks = set(range(num_blocks))
self.used_blocks = set()
def allocate(self) -> int:
"""分配一个空闲块"""
if not self.free_blocks:
raise RuntimeError("No free blocks available")
block_id = next(iter(self.free_blocks))
self.free_blocks.remove(block_id)
self.used_blocks.add(block_id)
return block_id
def free(self, block_id: int) -> None:
"""释放一个块"""
self.used_blocks.remove(block_id)
self.free_blocks.add(block_id)
- BlockTable:维护序列到物理块的映射
class BlockTable:
def __init__(self, block_size: int):
self.block_size = block_size
self.tables = {} # seq_id -> List[block_id]
def add_block(self, seq_id: int, block_id: int) -> None:
"""为序列添加一个块"""
if seq_id not in self.tables:
self.tables[seq_id] = []
self.tables[seq_id].append(block_id)
def get_physical_blocks(self, seq_id: int, positions: torch.Tensor) -> Tuple[List[int], torch.Tensor]:
"""获取物理块 ID 和偏移量"""
block_ids = self.tables[seq_id]
block_indices = positions // self.block_size
block_offsets = positions % self.block_size
physical_blocks = [block_ids[idx.item()] for idx in block_indices]
return physical_blocks, block_offsets
- 注意力计算核心:高效实现分块注意力计算
# CUDA 核心伪代码
@cuda.kernel
def paged_attention_kernel(
q: Tensor, # [batch_size, num_heads, head_dim]
k_cache: Tensor, # [num_blocks, block_size, num_heads, head_dim]
v_cache: Tensor, # [num_blocks, block_size, num_heads, head_dim]
block_tables: Tensor, # [batch_size, max_blocks]
output: Tensor # [batch_size, num_heads, head_dim]
):
# 获取线程索引
batch_idx = cuda.blockIdx.x
head_idx = cuda.blockIdx.y
# 获取该序列的块表
seq_blocks = block_tables[batch_idx]
# 本地计算缓冲区
local_k = shared_memory[...]
local_v = shared_memory[...]
# 加载查询向量
query = q[batch_idx, head_idx]
# 对每个块执行注意力计算
for i in range(len(seq_blocks)):
block_id = seq_blocks[i]
# 加载 KV 缓存到共享内存
local_k.copy_from(k_cache[block_id])
local_v.copy_from(v_cache[block_id])
# 计算注意力分数
scores = compute_attention(query, local_k)
# 应用注意力权重
output[batch_idx, head_idx] += apply_attention(scores, local_v)
性能优势
PagedAttention 带来了多项显著优势:
- 内存效率:通过分块和动态分配,显著减少内存碎片
- 传统方法:为每个序列分配最大长度的连续内存
- PagedAttention:按需分配块,高效共享物理内存
- 批处理吞吐量:支持更多并发请求
- 实验表明,相同硬件上,vLLM 可以处理比其他框架多 2-4 倍的并发请求
- 长文本支持:优雅处理长序列生成
- 只需添加新块,无需重新分配或复制整个缓存
- 内存利用率:内存使用量与实际 token 数成正比,而非预分配
- 典型场景中,与传统方法相比,内存使用可减少 50-70%
实际应用案例
在 vLLM 中,PagedAttention 的应用可以在多方面观察到:
- 动态批处理:高效支持连续批处理(Continuous Batching)
# 在每次前向传播中添加新序列 def step(self): # 调度新序列和正在进行的序列 scheduled_seq_groups = self.scheduler.schedule() if not scheduled_seq_groups: return # 准备批处理输入 batch = self._prepare_batch(scheduled_seq_groups) # 为新序列分配 KV 缓存块 for seq_id in batch.new_seq_ids: self.block_manager.allocate_blocks(seq_id, batch.prompt_lens[seq_id]) # 执行模型前向传播 outputs = self.model_runner.forward(batch.input_ids, batch.block_tables, ...) - 高效内存管理:动态分配和回收物理块
def free_finished_sequences(self): """释放已完成序列的内存""" for seq_id in self.finished_sequences: # 获取分配的块 blocks = self.block_tables.get_blocks(seq_id) # 释放块 for block_id in blocks: self.block_allocator.free(block_id) # 移除块表条目 self.block_tables.remove(seq_id) - 缓存共享:支持 fork 和复制操作
def fork_sequence(self, src_seq_id: int, dst_seq_id: int, fork_pos: int): """分叉序列,复用 KV 缓存""" # 获取源序列的块表 src_blocks = self.block_tables.get_blocks(src_seq_id) # 计算 fork 位置对应的块 fork_block_idx = fork_pos // self.block_size # 共享前 fork_block_idx 个块 shared_blocks = src_blocks[:fork_block_idx] # 为新序列创建块表,共享已有块 self.block_tables.create(dst_seq_id, shared_blocks) # 从 fork 位置开始分配新块 return dst_seq_id
总的来说,PagedAttention 是 vLLM 的关键创新,它解决了大语言模型推理中的内存效率问题,使得服务能够以更低的成本处理更多并发请求,同时支持更长的文本生成。这种设计灵感来自操作系统的虚拟内存管理,证明了经典计算机科学原理在现代 AI 系统中的价值。
5.2 连续批处理技术
连续批处理(Continuous Batching)是 vLLM 中与 PagedAttention 配合使用的关键技术,它解决了传统批处理在 LLM 推理中的效率问题。
传统批处理的局限性
传统的批处理策略(Static Batching)存在几个主要问题:
- 请求同步问题:所有序列必须同时启动和结束
# 传统批处理示例 def static_batch_inference(model, prompts): # 编码所有输入 input_ids = tokenizer(prompts, padding=True, return_tensors="pt") # 所有序列同时开始生成 outputs = model.generate( input_ids, max_length=max_length, num_return_sequences=1, ) # 所有序列必须等待最长的序列完成 return tokenizer.batch_decode(outputs) - 计算资源浪费:
- 长序列会使短序列等待
- GPU 利用率低下
- 每批次间存在空闲时间
- 延迟问题:
- 新请求必须等待当前批次完成
- 平均等待时间长
连续批处理原理
连续批处理允许动态添加和移除序列,无需等待整个批次完成:
class ContinuousBatcher:
def __init__(self):
self.active_sequences = {} # 活跃序列集合
self.waiting_sequences = Queue() # 等待队列
def add_sequence(self, seq_id, prompt):
"""添加新序列到等待队列"""
self.waiting_sequences.put((seq_id, prompt))
def step(self, model):
"""执行一步批处理"""
# 1. 调度可执行序列
batch = self._schedule_batch()
# 2. 执行模型推理
outputs = model.forward(batch.input_ids)
# 3. 处理结果
for seq_id, output in zip(batch.seq_ids, outputs):
self._process_output(seq_id, output)
# 4. 移除已完成序列
self._cleanup_finished_sequences()
def _schedule_batch(self):
"""调度当前步骤的批次"""
batch = Batch()
# 添加活跃序列
for seq_id, seq in self.active_sequences.items():
if not seq.is_finished:
batch.add(seq_id, seq.get_next_input())
# 尝试添加新序列(如果有空间)
while len(batch) < self.max_batch_size and not self.waiting_sequences.empty():
seq_id, prompt = self.waiting_sequences.get()
self.active_sequences[seq_id] = Sequence(prompt)
batch.add(seq_id, self.active_sequences[seq_id].get_next_input())
return batch
工作流程:
- 动态加入:新请求可以在任何时间点加入批处理
- 并行处理:不同长度和进度的序列可以同时处理
- 动态退出:完成的序列立即释放资源
- 资源调度:根据当前负载动态调整批大小
vLLM 的实现细节
在 vLLM 中,连续批处理由 Scheduler 和 Engine 类协同实现:
- 请求调度器:管理请求队列和调度决策
class Scheduler:
def __init__(self, max_num_seqs: int, max_num_tokens: int):
self.max_num_seqs = max_num_seqs # 最大序列数
self.max_num_tokens = max_num_tokens # 最大 token 数
self.waiting = [] # 等待队列
self.running = {} # 运行中的序列
self.swapped = {} # 被换出的序列
def schedule(self) -> List[SequenceGroup]:
"""调度下一批序列"""
scheduled = []
# 优先调度运行中的序列
running_ready = [seq for seq in self.running.values() if seq.is_ready()]
scheduled.extend(running_ready)
# 如果有剩余资源,从等待队列调度新序列
remaining_capacity = self._get_remaining_capacity(scheduled)
if remaining_capacity.can_schedule():
new_seqs = self._schedule_from_waiting(remaining_capacity)
scheduled.extend(new_seqs)
return scheduled
def add_request(self, request):
"""添加新请求到等待队列"""
self.waiting.append(request)
def abort_request(self, request_id):
"""中止请求"""
# 从所有队列中移除
# ...
def _schedule_from_waiting(self, capacity):
"""从等待队列调度序列"""
scheduled = []
remaining_seqs = capacity.max_seqs
remaining_tokens = capacity.max_tokens
# 使用优先级排序等待队列
self.waiting.sort(key=lambda x: x.priority, reverse=True)
for seq in self.waiting:
# 检查是否有足够资源
if remaining_seqs > 0 and remaining_tokens >= seq.token_count:
scheduled.append(seq)
self.waiting.remove(seq)
self.running[seq.id] = seq
# 更新剩余容量
remaining_seqs -= 1
remaining_tokens -= seq.token_count
return scheduled
- 引擎核心:执行实际批处理
class Engine:
def __init__(self, model, scheduler):
self.model = model
self.scheduler = scheduler
self.running_sequences = {}
def add_request(self, request):
"""添加新请求"""
self.scheduler.add_request(request)
def step(self):
"""执行一步批处理"""
# 1. 调度序列
scheduled = self.scheduler.schedule()
if not scheduled:
return None
# 2. 准备批处理输入
batch = self._prepare_batch(scheduled)
# 3. 执行模型推理
outputs = self.model.forward(batch.input_ids, batch.attention_mask)
# 4. 处理输出
self._process_outputs(outputs, batch)
# 5. 返回生成的 token
return self._get_outputs()
def _prepare_batch(self, scheduled):
"""准备批处理输入"""
batch = Batch()
for seq in scheduled:
if seq.id in self.running_sequences:
# 继续生成
input_id = self.running_sequences[seq.id].last_token
else:
# 新序列,处理提示
input_ids = self._tokenize(seq.prompt)
self.running_sequences[seq.id] = RunningSequence(seq.id, input_ids)
batch.add(seq)
return batch
def _process_outputs(self, outputs, batch):
"""处理模型输出"""
for i, seq_id in enumerate(batch.seq_ids):
# 获取下一个 token
next_token = outputs.logits[i].argmax(-1).item()
# 更新序列
self.running_sequences[seq_id].append_token(next_token)
# 检查是否完成
if self._is_finished(seq_id, next_token):
seq = self.running_sequences.pop(seq_id)
self.scheduler.finish_sequence(seq_id)
优化技术
vLLM 在连续批处理基础上还引入了多项优化:
- 迭代式调度:每轮迭代动态调整批大小,最大化 GPU 利用率
def iterative_schedule(self):
"""迭代调度以最大化 GPU 利用率"""
# 初始化批次
batch = Batch()
# 迭代添加序列,直到达到资源限制
while True:
# 尝试添加下一个序列
next_seq = self._get_next_candidate()
if next_seq is None:
break
# 计算添加后的资源使用
new_resource_usage = self._calculate_resource_usage(batch, next_seq)
# 如果超出资源限制,停止添加
if new_resource_usage > self.max_resource_limit:
break
# 添加到批次
batch.add(next_seq)
return batch
- 预取优化:提前加载下一批次数据
def prefetch_next_batch(self):
"""预取下一批次数据"""
# 预测下一步可能调度的序列
predicted_next = self.scheduler.peek_next_batch()
# 异步预加载数据
asyncio.create_task(self._async_prefetch(predicted_next))
def _async_prefetch(self, sequences):
"""异步预加载数据"""
for seq in sequences:
if seq.id not in self.prefetched_data:
# 预处理输入
processed_data = self._preprocess(seq)
# 存储预处理结果
self.prefetched_data[seq.id] = processed_data
- 优先级调度:基于等待时间和优先级的混合调度策略
def priority_schedule(self):
"""基于优先级的调度"""
# 计算每个请求的综合优先级分数
for req in self.waiting:
# 基础优先级
priority = req.priority
# 等待时间因子
wait_time = time.time() - req.arrival_time
wait_factor = min(1.0, wait_time / self.max_wait_time)
# 综合分数 (混合优先级和等待时间)
req.score = priority * 0.7 + wait_factor * 0.3
# 按分数排序
self.waiting.sort(key=lambda x: x.score, reverse=True)
# 调度顶部序列
return self.waiting[:self.max_batch_size]
性能优势
连续批处理带来的性能优势包括:
- 吞吐量提升:
- 减少 GPU 空闲时间
- 在相同硬件上支持更多并发请求
- 响应延迟降低:
- 新请求不必等待整个批次完成
- 短序列可以更快完成,不受长序列影响
- 资源利用率提高:
- GPU 利用率从传统的 30-40% 提升至 80-90%
- 内存使用更加高效,随时释放完成序列资源
- 服务质量改进:
- 支持请求优先级
- 更公平的资源分配
实际应用案例
在 vLLM 中,连续批处理结合 PagedAttention,形成了高效的推理引擎:
# vLLM 引擎主循环
def _run_engine(self):
"""vLLM 引擎主循环"""
while not self._stop_event.is_set():
# 调度序列
scheduled_seq_groups = self.scheduler.schedule()
if not scheduled_seq_groups:
time.sleep(0.001) # 避免空转
continue
# 准备批次
batch = self._prepare_batch(scheduled_seq_groups)
# 执行模型前向传播
outputs = self.model_runner.execute_model(
batch.input_ids,
batch.positions,
batch.kv_caches,
batch.block_tables,
)
# 后处理结果
self._process_model_outputs(outputs, batch)
# 检查完成的序列
self._check_completion(batch.seq_groups)
连续批处理允许 vLLM 在处理大量并发请求时保持高吞吐量和低延迟,这对于构建可扩展的 LLM 服务至关重要。结合 PagedAttention 的内存优化,vLLM 能够高效地管理序列生命周期和计算资源,为大规模 LLM 服务提供关键支持。
5.3 CUDA 图捕获与加速
vLLM 使用 CUDA 图(CUDA Graph)技术显著加速模型推理过程。这种技术通过预先记录和优化 GPU 操作序列,减少 CPU-GPU 交互开销,提高吞吐量和降低延迟。
CUDA 图基本原理
CUDA 图是 NVIDIA GPU 编程中的一项高级功能,允许将一系列 GPU 操作(包括内核启动、内存复制等)预先捕获为一个图,然后重复执行:
# 传统 CUDA 执行方式
for i in range(iterations):
# 每次迭代都需要 CPU-GPU 通信和调度开销
kernel1<<<grid, block>>>(args1); # CPU 调度 GPU 执行
kernel2<<<grid, block>>>(args2); # CPU 调度 GPU 执行
# CUDA 图执行方式
# 1. 捕获阶段(只执行一次)
cudaStreamBeginCapture(stream);
kernel1<<<grid, block, 0, stream>>>(args1);
kernel2<<<grid, block, 0, stream>>>(args2);
cudaGraph_t graph;
cudaStreamEndCapture(stream, &graph);
# 2. 实例化图(只执行一次)
cudaGraphExec_t graphExec;
cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0);
# 3. 重复执行(高效)
for i in range(iterations):
# 无需 CPU 干预,极低开销
cudaGraphLaunch(graphExec, stream);
CUDA 图的主要优势:
- 减少 CPU 开销:降低 kernel 调度和参数传递的延迟
- 优化 GPU 执行:允许 CUDA 运行时预先优化整个计算图
- 更好的并行性:提高 GPU 流水线效率
- 确定性执行:一致的执行模式和时间
vLLM 中的 CUDA 图实现
vLLM 在 ModelRunner 类中实现了 CUDA 图捕获机制,主要通过 capture_model 方法完成:
@torch.inference_mode()
def capture_model(self, kv_caches: List[List[torch.Tensor]]) -> None:
"""捕获模型执行为 CUDA 图以加速推理"""
# 1. 准备捕获环境
self._check_if_cuda_graphs_supported()
# 保存当前内存状态,在捕获后释放临时内存
mempool = torch.cuda.graph_pool_handle()
self.graph_memory_pool = mempool
self.dummy_inputs = {}
self.graph_runners = {}
# 2. 获取批处理大小
batch_sizes = self._get_graph_batch_sizes()
# 3. 为每个批处理大小捕获图
for batch_size in batch_sizes:
# 准备虚拟模型输入(重要!)
dummy_inputs = self._prepare_dummy_inputs(batch_size)
self.dummy_inputs[batch_size] = dummy_inputs
# 捕获模型前向传播
with self.attn_state.graph_capture(batch_size), \
cuda_graph_context(self.device) as context:
# 执行捕获
outputs = self._forward_helper(**dummy_inputs)
# 创建图运行器
self.graph_runners[batch_size] = CUDAGraphRunner(
context.graph, dummy_inputs, outputs
)
# 4. 设置已捕获标志
self.model_captured = True
这个方法执行以下核心步骤:
- 环境检查与设置:验证硬件和软件支持 CUDA 图,并准备内存池
- 批处理尺寸确定:计算需要支持的批处理大小
- 准备虚拟输入:为每个批处理大小创建固定形状的输入张量
- 捕获过程:在特定环境下执行一次模型前向传播,捕获所有 CUDA 操作
- 图实例化:将捕获的图转换为可执行实例,存储在
graph_runners中
关键组件:CUDAGraphRunner
CUDAGraphRunner 类封装了 CUDA 图的管理和执行逻辑:
class CUDAGraphRunner:
"""管理 CUDA 图的捕获和执行"""
def __init__(self, graph, static_inputs, static_outputs):
# 存储图和静态内存引用
self.graph = graph
self.static_inputs = static_inputs
self.static_outputs = static_outputs
def capture(self, **inputs):
"""执行并捕获计算图"""
# 使用指定输入执行一次前向传播,让 CUDA 记录操作序列
with torch.cuda.graph(self.graph):
# 更新静态输入
for name, tensor in inputs.items():
self.static_inputs[name].copy_(tensor)
# 捕获前向传播
self.static_outputs = self.forward_fn(**self.static_inputs)
return self
def forward(self, **inputs):
"""使用CUDA图执行前向传播"""
# 更新输入数据
for name, tensor in inputs.items():
self.static_inputs[name].copy_(tensor)
# 执行图 - 高效!
self.graph.replay()
return self.static_outputs
这个类负责两个主要任务:
- 图捕获:在初始化时记录计算图
- 高效执行:在推理阶段重播图,避免 CPU 调度开销
虚拟输入的重要性
CUDA 图要求输入张量的形状和内存地址在每次执行时保持不变。因此,vLLM 使用”虚拟输入”策略:
def _prepare_dummy_inputs(self, batch_size: int) -> Dict[str, torch.Tensor]:
"""准备用于图捕获的虚拟输入"""
# 1. 创建固定形状的输入张量
input_ids = torch.zeros(
batch_size, dtype=torch.long, device=self.device
)
# 2. 分配位置 ID
positions = torch.zeros(
batch_size, dtype=torch.long, device=self.device
)
# 3. 创建注意力掩码
attention_mask = torch.ones(
batch_size, self.max_context_len, dtype=torch.bool, device=self.device
)
# 4. 准备 KV 缓存和块表
# 此处省略复杂的 KV 缓存准备逻辑...
return {
"input_ids": input_ids,
"positions": positions,
"attention_mask": attention_mask,
"kv_caches": kv_caches,
"block_tables": block_tables,
}
在实际执行时,模型会先将真实输入复制到这些预分配的虚拟张量中,然后执行图:
def execute_model(self, input_ids, positions, kv_caches, block_tables):
"""执行模型前向传播"""
batch_size = input_ids.shape[0]
# 如果已捕获且批处理大小匹配,使用 CUDA 图
if self.model_captured and batch_size in self.graph_runners:
# 准备输入
inputs = {
"input_ids": input_ids,
"positions": positions,
"kv_caches": kv_caches,
"block_tables": block_tables,
}
# 使用图运行器 - 高性能路径
return self.graph_runners[batch_size].forward(**inputs)
else:
# 标准执行路径
return self._forward_helper(
input_ids, positions, kv_caches, block_tables
)
技术挑战与解决方案
CUDA 图实现面临几个技术挑战:
- 内存地址固定要求:
- 挑战:CUDA 图要求输入/输出张量地址不变
- 解决方案:使用预分配的静态内存,通过
copy_更新内容
- 动态形状处理:
- 挑战:不同批处理大小需要不同图
- 解决方案:为常见批处理大小预捕获多个图
- 内存管理:
- 挑战:图捕获可能导致内存泄漏
- 解决方案:使用 PyTorch 的图内存池,并在捕获后释放临时资源
- 动态控制流:
- 挑战:CUDA 图不支持动态控制流
- 解决方案:固定解码器路径,移除条件分支
CUDA 图捕获的优化策略
vLLM 采用了几个关键策略优化 CUDA 图性能:
- 分段捕获:
# 为模型不同部分捕获独立图 self.embedding_graph = self._capture_embedding_graph() self.decoder_graphs = {} for layer_idx in range(self.num_layers): self.decoder_graphs[layer_idx] = self._capture_decoder_layer(layer_idx) self.final_layer_graph = self._capture_final_layer() - 预热策略:
def warmup_model(self): """预热模型,确保图捕获前性能稳定""" # 使用典型批处理大小执行几次前向传播 dummy_batch = self._create_dummy_batch(self.max_batch_size) for _ in range(3): # 执行几轮预热 self._forward_helper(**dummy_batch) torch.cuda.synchronize() - 分层缓存:
def _get_graph_batch_sizes(self): """确定需要捕获的批处理大小集合""" # 使用分层策略,覆盖常见大小 # 小批量:精确捕获 # 中批量:对数间隔捕获 # 大批量:线性间隔捕获 sizes = [] # 小批量(每个大小都捕获) sizes.extend(range(1, 17)) # 中批量(对数间隔) sizes.extend([24, 32, 48, 64]) # 大批量(线性间隔) sizes.extend([96, 128, 192, 256]) return [s for s in sizes if s <= self.max_batch_size]
性能收益
CUDA 图捕获为 vLLM 带来显著性能提升:
- 吞吐量提升:
- 对于批量大小 8 的推理,吞吐量提高 15-30%
- 对于批量大小 32 的推理,吞吐量提高 25-40%
- 延迟降低:
- 单个请求延迟减少 8-15%
- 批处理请求平均延迟减少 20-35%
- CPU 负载降低:
- CPU 使用率降低 30-50%,减轻调度瓶颈
使用限制与注意事项
尽管 CUDA 图提供了显著的性能优势,但也有一些限制需要注意:
- 固定输入形状:每个批处理大小需要单独的图
- 控制流限制:不支持动态分支和循环
- 内存消耗:维护多个图会增加 GPU 内存使用
- 调试困难:错误追踪更加复杂
- 硬件依赖:性能提升受 GPU 架构影响
实际应用示例
在 vLLM 的实际使用中,CUDA 图捕获的应用如下:
# 在 model_runner.py 的 execute_model 方法中
def execute_model(self, *args, **kwargs):
"""执行模型推理,自动选择最佳路径"""
batch_size = kwargs["input_ids"].shape[0]
# 选择执行路径
if (self.model_captured and
batch_size in self.graph_runners and
not self.config.disable_cuda_graphs):
# CUDA 图路径 - 高性能
start_time = time.time()
outputs = self._execute_with_graph(batch_size, *args, **kwargs)
if self.profiler:
self.profiler.record_cuda_graph_execution(time.time() - start_time)
return outputs
else:
# 常规执行路径
return self._execute_standard(*args, **kwargs)
实际的推理框架中,会自动选择使用 CUDA 图或标准执行路径,确保最佳性能。
总结而言,CUDA 图捕获是 vLLM 性能优化的关键组成部分,通过减少 CPU-GPU 交互开销,显著提高模型的推理吞吐量和降低延迟。这一技术特别适用于具有稳定形状和计算模式的大型语言模型推理场景。
5.4 KV 缓存管理
KV 缓存(Key-Value Cache)是大型语言模型自回归生成中的关键优化技术,它存储先前计算的注意力键值对,避免重复计算。vLLM 通过创新的缓存管理机制,使这一技术在大规模服务中更加高效。
KV 缓存基本原理
在 Transformer 的自回归解码中,每生成一个新 token,都需要计算该 token 与所有先前 token 的注意力:
# 未使用 KV 缓存的自回归生成
for i in range(max_seq_len):
# 对所有已生成的 token 重新计算 K 和 V
keys = self.compute_keys(input_ids[:, :i+1]) # 重复计算
values = self.compute_values(input_ids[:, :i+1]) # 重复计算
# 计算下一个 token 的输出
next_token_logits = self.compute_attention(
query=self.compute_query(input_ids[:, i:i+1]),
keys=keys,
values=values
)
# 采样下一个 token
next_token = sample(next_token_logits)
input_ids = torch.cat([input_ids, next_token], dim=1)
使用 KV 缓存后,先前计算的 K 和 V 被保留下来,只需为新 token 计算:
# 使用 KV 缓存的自回归生成
# 初始化缓存
key_cache = []
value_cache = []
for i in range(max_seq_len):
if i == 0:
# 处理提示词
keys = self.compute_keys(input_ids)
values = self.compute_values(input_ids)
# 存入缓存
key_cache.append(keys)
value_cache.append(values)
else:
# 只计算最新 token 的 K 和 V
new_key = self.compute_keys(input_ids[:, -1:])
new_value = self.compute_values(input_ids[:, -1:])
# 添加到缓存
key_cache.append(new_key)
value_cache.append(new_value)
# 使用完整缓存计算注意力
next_token_logits = self.compute_attention(
query=self.compute_query(input_ids[:, -1:]),
keys=torch.cat(key_cache, dim=1),
values=torch.cat(value_cache, dim=1)
)
# 采样下一个 token
next_token = sample(next_token_logits)
input_ids = torch.cat([input_ids, next_token], dim=1)
这一优化将时间复杂度从 O(n²) 降低到 O(n),其中 n 是序列长度。
vLLM 中的缓存结构
vLLM 使用层次化的结构管理 KV 缓存:
class KVCacheManager:
def __init__(self, num_layers, num_heads, head_size, block_size):
self.num_layers = num_layers
self.num_heads = num_heads
self.head_size = head_size
self.block_size = block_size
# 物理缓存存储
self.key_blocks = torch.empty(
(0, block_size, num_heads, head_size),
dtype=torch.float16, device="cuda"
)
self.value_blocks = torch.empty(
(0, block_size, num_heads, head_size),
dtype=torch.float16, device="cuda"
)
# 块分配器
self.block_allocator = BlockAllocator()
# 序列到块的映射
self.block_tables = {}
vLLM 的 KV 缓存管理分为以下几个层级:
- 物理存储层:实际存储 K 和 V 的张量块
- 分配管理层:负责分配和回收物理块
- 逻辑映射层:维护序列 ID 到物理块的映射
- 访问控制层:提供高效的缓存读写接口
缓存分配与释放
缓存的分配和释放是 vLLM 内存管理的核心:
def allocate_kv_cache(self, seq_id: int, prompt_len: int) -> None:
"""为新序列分配 KV 缓存"""
# 计算需要的块数
num_blocks = ceil_div(prompt_len, self.block_size)
# 分配物理块
block_ids = []
for _ in range(num_blocks):
block_id = self.block_allocator.allocate()
if block_id >= len(self.key_blocks):
# 缓存扩容
self._extend_cache(block_id + 1 - len(self.key_blocks))
block_ids.append(block_id)
# 更新块表
self.block_tables[seq_id] = block_ids
def free_kv_cache(self, seq_id: int) -> None:
"""释放序列的 KV 缓存"""
if seq_id not in self.block_tables:
return
# 获取分配的块
block_ids = self.block_tables[seq_id]
# 释放块
for block_id in block_ids:
self.block_allocator.free(block_id)
# 移除映射
del self.block_tables[seq_id]
缓存扩容是一个关键操作,它在需要更多物理块时动态调整缓存大小:
def _extend_cache(self, num_blocks: int) -> None:
"""扩展 KV 缓存"""
current_size = len(self.key_blocks)
new_size = current_size + num_blocks
# 创建新存储空间
new_key_blocks = torch.empty(
(new_size, self.block_size, self.num_heads, self.head_size),
dtype=torch.float16, device="cuda"
)
new_value_blocks = torch.empty(
(new_size, self.block_size, self.num_heads, self.head_size),
dtype=torch.float16, device="cuda"
)
# 复制现有数据
if current_size > 0:
new_key_blocks[:current_size] = self.key_blocks
new_value_blocks[:current_size] = self.value_blocks
# 替换缓存
self.key_blocks = new_key_blocks
self.value_blocks = new_value_blocks
缓存访问与更新
高效的缓存访问对性能至关重要:
def get_kv_cache(self, seq_id: int, positions: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
"""获取特定位置的 KV 缓存"""
if seq_id not in self.block_tables:
return None, None
# 获取块表
block_table = self.block_tables[seq_id]
# 计算块索引和偏移
block_indices = positions // self.block_size
block_offsets = positions % self.block_size
# 构建批索引张量
indices_tensor = torch.empty(
(len(positions), 3), dtype=torch.long, device="cuda"
)
# 填充索引 [block_idx, block_offset, head_idx]
for i, (block_idx, offset) in enumerate(zip(block_indices, block_offsets)):
indices_tensor[i, 0] = block_table[block_idx.item()]
indices_tensor[i, 1] = offset
# 提取缓存
keys = torch.index_select(
self.key_blocks.view(-1, self.num_heads, self.head_size),
0, indices_tensor[:, 0] * self.block_size + indices_tensor[:, 1]
)
values = torch.index_select(
self.value_blocks.view(-1, self.num_heads, self.head_size),
0, indices_tensor[:, 0] * self.block_size + indices_tensor[:, 1]
)
return keys, values
在 vLLM 实际实现中,使用了更高效的 CUDA 自定义内核来加速缓存访问:
# CUDA 内核(伪代码)
@cuda.jit
def paged_attention_kernel(
query, # [batch_size, num_heads, head_size]
key_cache, # [num_blocks, block_size, num_heads, head_size]
value_cache, # [num_blocks, block_size, num_heads, head_size]
block_tables, # [batch_size, max_blocks_per_seq]
seq_lens, # [batch_size]
output # [batch_size, num_heads, head_size]
):
# 获取线程索引
batch_idx = cuda.blockIdx.x
head_idx = cuda.blockIdx.y
# 获取序列的块表和长度
seq_block_table = block_tables[batch_idx]
seq_len = seq_lens[batch_idx]
# 获取当前查询向量
q = query[batch_idx, head_idx]
# 计算注意力分数和加权和
acc = cuda.local.array(shape=(HEAD_SIZE,), dtype=float32)
for i in range(HEAD_SIZE):
acc[i] = 0.0
# 遍历序列的所有块
for block_idx in range(ceil_div(seq_len, BLOCK_SIZE)):
physical_block = seq_block_table[block_idx]
block_len = min(BLOCK_SIZE, seq_len - block_idx * BLOCK_SIZE)
# 计算注意力分数
scores = cuda.local.array(shape=(BLOCK_SIZE,), dtype=float32)
for i in range(block_len):
k = key_cache[physical_block, i, head_idx]
scores[i] = dot_product(q, k)
# 应用 softmax
softmax_normalization(scores, block_len)
# 计算加权和
for i in range(block_len):
v = value_cache[physical_block, i, head_idx]
for j in range(HEAD_SIZE):
acc[j] += scores[i] * v[j]
# 写回输出
for i in range(HEAD_SIZE):
output[batch_idx, head_idx, i] = acc[i]
这个 CUDA 内核直接在 GPU 上执行分块注意力计算,避免了将分散的块复制到连续内存的开销。
序列复制与分叉
vLLM 支持序列复制和分叉操作,这对于并行采样和树搜索算法至关重要:
def fork_sequence(
self, src_seq_id: int, dst_seq_id: int, fork_pos: int
) -> None:
"""在指定位置分叉序列,共享 KV 缓存"""
if src_seq_id not in self.block_tables:
return
# 获取源序列的块表
src_blocks = self.block_tables[src_seq_id]
# 计算分叉位置对应的块
fork_block_idx = fork_pos // self.block_size
# 共享前 fork_block_idx 个块
shared_blocks = src_blocks[:fork_block_idx + 1]
# 复制源块引用
if dst_seq_id in self.block_tables:
# 清理可能的现有块
self.free_kv_cache(dst_seq_id)
# 创建新的块表
self.block_tables[dst_seq_id] = shared_blocks.copy()
# 增加共享块的引用计数
for block_id in shared_blocks:
self.block_allocator.increment_ref_count(block_id)
这种机制允许多个序列共享公共前缀的 KV 缓存,同时维护各自的后续缓存,大大节省了内存和计算资源。
缓存交换与重用
为了支持更多并发序列,vLLM 实现了缓存交换机制,将不活跃序列的缓存暂时移出 GPU:
def swap_out(self, seq_id: int) -> Dict:
"""将序列缓存交换出 GPU"""
if seq_id not in self.block_tables:
return None
# 获取块表
block_ids = self.block_tables[seq_id]
# 准备 CPU 存储
cpu_key_cache = []
cpu_value_cache = []
# 复制到 CPU
for block_id in block_ids:
cpu_key_cache.append(
self.key_blocks[block_id].detach().cpu()
)
cpu_value_cache.append(
self.value_blocks[block_id].detach().cpu()
)
# 释放 GPU 块
self.free_kv_cache(seq_id)
# 返回 CPU 缓存
return {
"block_table": block_ids,
"key_cache": cpu_key_cache,
"value_cache": cpu_value_cache
}
def swap_in(self, seq_id: int, cpu_cache: Dict) -> None:
"""将序列缓存交换回 GPU"""
# 提取 CPU 缓存
block_table = cpu_cache["block_table"]
cpu_key_cache = cpu_cache["key_cache"]
cpu_value_cache = cpu_cache["value_cache"]
# 分配新块
new_block_ids = []
for i in range(len(block_table)):
# 分配块
block_id = self.block_allocator.allocate()
if block_id >= len(self.key_blocks):
self._extend_cache(block_id + 1 - len(self.key_blocks))
# 将数据复制回 GPU
self.key_blocks[block_id].copy_(
cpu_key_cache[i].to("cuda")
)
self.value_blocks[block_id].copy_(
cpu_value_cache[i].to("cuda")
)
new_block_ids.append(block_id)
# 更新块表
self.block_tables[seq_id] = new_block_ids
这种交换机制使 vLLM 能够处理超出 GPU 内存容量的并发请求,通过智能调度,优先处理活跃序列。
优化策略
vLLM 在 KV 缓存管理中采用了多种优化策略:
- 预分配策略:
def preallocate_cache(self, max_seq_len: int, batch_size: int) -> None: """预分配 KV 缓存空间""" num_blocks_per_seq = ceil_div(max_seq_len, self.block_size) total_blocks = num_blocks_per_seq * batch_size if len(self.key_blocks) < total_blocks: self._extend_cache(total_blocks - len(self.key_blocks)) - 缓存压缩:降低精度以节省内存
def compress_cache(self) -> None: """将 KV 缓存压缩为更低精度""" if self.key_blocks.dtype != torch.float16: return # 将 float16 转换为 int8 self.key_blocks_int8 = quantize(self.key_blocks) self.value_blocks_int8 = quantize(self.value_blocks) # 释放原始存储 del self.key_blocks del self.value_blocks # 更新标志 self.using_compressed_cache = True - 层级缓存:不同层使用不同精度
def use_mixed_precision_cache(self) -> None: """对不同层使用不同精度缓存""" for i in range(self.num_layers): # 前几层使用低精度(对精度不太敏感) if i < self.num_layers // 3: self.layer_precisions[i] = "int8" # 中间层使用中等精度 elif i < self.num_layers * 2 // 3: self.layer_precisions[i] = "fp16" # 后几层使用高精度(对精度更敏感) else: self.layer_precisions[i] = "fp32"
实际应用示例
在 vLLM 引擎的循环中,KV 缓存管理的应用如下:
def step(self):
"""执行一步生成"""
# 1. 调度序列
scheduled = self.scheduler.schedule()
# 2. 准备批处理输入
batch = self._prepare_batch(scheduled)
# 3. 为新序列分配 KV 缓存
for seq_id in batch.new_seq_ids:
self.cache_manager.allocate_kv_cache(
seq_id, batch.prompt_lens[seq_id]
)
# 4. 执行模型前向传播
outputs = self.model_runner.forward(
batch.input_ids,
batch.positions,
batch.kv_caches,
batch.block_tables
)
# 5. 处理输出并更新序列状态
for i, seq_id in enumerate(batch.seq_ids):
# 采样下一个 token
next_token = self._sample_next_token(outputs, i)
# 添加到序列
self.sequences[seq_id].append_token(next_token)
# 检查是否完成
if self._is_finished(seq_id):
# 释放 KV 缓存
self.cache_manager.free_kv_cache(seq_id)
总的来说,vLLM 的 KV 缓存管理系统结合了 PagedAttention 机制、动态内存分配和高效的 CUDA 内核,解决了大规模 LLM 服务中的内存效率和计算性能挑战。通过这些优化,vLLM 能够在有限的 GPU 内存中支持更多并发请求和更长的序列长度,为构建响应式的 LLM 服务提供了基础。
5.5 内存优化策略
vLLM 实现了多种内存优化策略,解决大型语言模型推理中的 GPU 内存瓶颈问题。这些策略从不同层面优化内存使用,提高服务的并发能力和稳定性。
内存压力来源
大型语言模型推理面临的主要内存压力来自三个方面:
- 模型权重:随着模型规模增长,权重参数占用大量内存
# 对于常见模型大小,权重内存需求 model_size_in_gb = num_parameters * dtype_size_in_bytes / (1024**3) # 例如,70B 模型使用 FP16 精度需要约 140GB 内存 - 激活值:模型前向传播过程中的中间激活值
# 激活值内存需求(每个序列) activation_size = num_layers * sequence_length * hidden_size * dtype_size - KV 缓存:自回归生成过程中存储的键值对
# KV 缓存内存需求(每个序列) kv_cache_size = num_layers * sequence_length * 2 * hidden_size * dtype_size
vLLM 的内存优化策略针对这三个方面分别进行了优化。
张量并行与模型分片
为了处理超大模型,vLLM 实现了张量并行(Tensor Parallelism)技术:
class ModelSharding:
def __init__(self, model, num_gpus):
self.num_gpus = num_gpus
self.model = model
self.tp_size = num_gpus # 张量并行度
def shard_model(self):
"""将模型分片到多个 GPU"""
# 1. 识别可并行层
tp_modules = []
for name, module in self.model.named_modules():
if isinstance(module, (nn.Linear, nn.Embedding)):
tp_modules.append((name, module))
# 2. 为每个分片创建子模型
self.devices = [f"cuda:{i}" for i in range(self.tp_size)]
self.shards = [copy.deepcopy(self.model) for _ in range(self.tp_size)]
# 3. 分割权重
for name, module in tp_modules:
if isinstance(module, nn.Linear):
# 沿输出维度分割线性层
self._shard_linear_layer(name)
elif isinstance(module, nn.Embedding):
# 沿词汇表维度分割嵌入层
self._shard_embedding_layer(name)
张量并行的核心实现包括权重分割和梯度同步:
def _shard_linear_layer(self, name):
"""分割线性层权重"""
original_weight = self.model.get_submodule(name).weight
original_shape = original_weight.shape
# 沿输出维度分割
split_size = original_shape[0] // self.tp_size
for i in range(self.tp_size):
# 计算分片范围
start_idx = i * split_size
end_idx = (i + 1) * split_size if i < self.tp_size - 1 else original_shape[0]
# 分配分片
shard = self.shards[i].get_submodule(name)
with torch.no_grad():
shard.weight = nn.Parameter(
original_weight[start_idx:end_idx].clone().to(self.devices[i])
)
# 更新形状
shard.in_features = original_shape[1]
shard.out_features = end_idx - start_idx
vLLM 使用自定义的并行前向传播来协调多 GPU 计算:
def tp_forward(self, input_tensor):
"""使用张量并行执行前向传播"""
# 1. 分发输入到各个设备
input_shards = []
for i in range(self.tp_size):
input_shards.append(input_tensor.to(self.devices[i]))
# 2. 并行执行每个分片
output_shards = []
for i in range(self.tp_size):
with torch.cuda.device(self.devices[i]):
output_shards.append(self.shards[i](input_shards[i]))
# 3. 合并结果
if isinstance(output_shards[0], torch.Tensor):
# 对于分割的线性层,沿输出维度合并
return torch.cat(output_shards, dim=-1)
else:
# 对于其他层,可能需要特殊处理
return self._merge_custom_outputs(output_shards)
量化与混合精度
vLLM 支持多种量化技术以降低内存需求:
def load_quantized_model(model_path, quantization="int8"):
"""加载量化模型"""
if quantization == "int8":
# 使用 INT8 量化
return load_int8_model(model_path)
elif quantization == "int4":
# 使用 INT4 量化
return load_int4_model(model_path)
elif quantization == "awq":
# 使用 AWQ 量化
return load_awq_model(model_path)
else:
# 默认加载全精度模型
return load_full_precision_model(model_path)
量化策略具体实现示例:
def load_int8_model(model_path):
"""加载 INT8 量化模型"""
# 1. 加载原始模型配置和权重
config = AutoConfig.from_pretrained(model_path)
model = AutoModelForCausalLM.from_config(config)
state_dict = torch.load(f"{model_path}/pytorch_model.bin")
# 2. 对每个权重进行量化
quantized_state_dict = {}
for name, param in state_dict.items():
# 跳过某些不应量化的层
if "ln" in name or "embedding" in name:
quantized_state_dict[name] = param
else:
# 执行 INT8 量化
quantized_param = quantize_to_int8(param)
quantized_state_dict[name] = quantized_param
# 3. 加载量化后的权重
model.load_state_dict(quantized_state_dict)
# 4. 注册自定义内核用于量化计算
replace_with_quantized_kernels(model)
return model
vLLM 还实现了更复杂的二阶量化和混合精度策略:
class MixedPrecisionManager:
def __init__(self, model):
self.model = model
def apply_mixed_precision(self):
"""应用混合精度策略"""
# 分析层的重要性
layer_importance = self._analyze_layer_importance()
# 应用不同精度
for name, module in self.model.named_modules():
if isinstance(module, nn.Linear):
layer_name = name.split(".")[-2] # 获取层名称
if layer_name in layer_importance:
importance = layer_importance[layer_name]
# 根据重要性选择精度
if importance > 0.8:
# 重要层使用更高精度
module.to(torch.float16)
elif importance > 0.5:
# 中等重要性使用 INT8
quantize_module_to_int8(module)
else:
# 低重要性使用 INT4
quantize_module_to_int4(module)
激活检查点
对于内存受限的场景,vLLM 实现了激活检查点(Activation Checkpointing)技术:
class ActivationCheckpointing:
def __init__(self, model):
self.model = model
def apply_checkpointing(self):
"""对模型应用激活检查点"""
for name, module in self.model.named_children():
if isinstance(module, TransformerLayer):
# 包装 Transformer 层使用检查点
self.model._modules[name] = torch.utils.checkpoint.checkpoint_wrapper(module)
实现自定义粒度的检查点,以平衡内存使用和计算开销:
def custom_checkpointing(self):
"""实现自定义粒度的检查点"""
checkpoint_layers = []
# 为每个 Transformer 层选择检查点策略
for i, layer in enumerate(self.model.layers):
if i % 2 == 0: # 偶数层:细粒度检查点
# 单独对 attention 和 mlp 应用检查点
layer.attention = torch.utils.checkpoint.checkpoint_wrapper(
layer.attention,
preserve_rng_state=False
)
layer.mlp = torch.utils.checkpoint.checkpoint_wrapper(
layer.mlp,
preserve_rng_state=False
)
else: # 奇数层:整层检查点
checkpoint_layers.append(layer)
# 对选择的层应用检查点
for layer in checkpoint_layers:
layer_index = self.model.layers.index(layer)
self.model.layers[layer_index] = torch.utils.checkpoint.checkpoint_wrapper(
layer,
preserve_rng_state=False
)
优化的内存管理器
vLLM 实现了自定义的内存管理器,更精细地控制内存分配和释放:
class GPUMemoryManager:
def __init__(self, device, max_memory_fraction=0.9):
self.device = device
self.max_memory = int(torch.cuda.get_device_properties(device).total_memory
* max_memory_fraction)
self.allocated = 0
self.buffers = {}
self.free_buffers = {}
def allocate(self, size, dtype):
"""分配内存缓冲区"""
# 检查现有的空闲缓冲区
buffer_key = (size, dtype)
if buffer_key in self.free_buffers and self.free_buffers[buffer_key]:
# 重用现有缓冲区
buffer = self.free_buffers[buffer_key].pop()
return buffer
# 检查内存限制
bytes_size = size * dtype_size(dtype)
if self.allocated + bytes_size > self.max_memory:
# 尝试回收内存
self._garbage_collect()
if self.allocated + bytes_size > self.max_memory:
raise RuntimeError(f"Out of memory: trying to allocate {bytes_size} bytes")
# 分配新缓冲区
buffer = torch.empty(size, dtype=dtype, device=self.device)
self.allocated += bytes_size
buffer_id = id(buffer)
self.buffers[buffer_id] = (buffer, size, dtype, bytes_size)
return buffer
def free(self, buffer):
"""释放缓冲区(移至空闲池)"""
buffer_id = id(buffer)
if buffer_id in self.buffers:
_, size, dtype, _ = self.buffers[buffer_id]
buffer_key = (size, dtype)
# 添加到空闲池
if buffer_key not in self.free_buffers:
self.free_buffers[buffer_key] = []
self.free_buffers[buffer_key].append(buffer)
def _garbage_collect(self):
"""强制垃圾回收释放内存"""
# 清除超过阈值的空闲缓冲区
for buffer_key in list(self.free_buffers.keys()):
if len(self.free_buffers[buffer_key]) > 5: # 保留一定数量的缓冲区
# 释放多余缓冲区
excess_buffers = self.free_buffers[buffer_key][5:]
self.free_buffers[buffer_key] = self.free_buffers[buffer_key][:5]
# 更新分配跟踪
for buffer in excess_buffers:
buffer_id = id(buffer)
if buffer_id in self.buffers:
_, _, _, bytes_size = self.buffers[buffer_id]
self.allocated -= bytes_size
del self.buffers[buffer_id]
# 明确删除引用
del excess_buffers
# 强制 PyTorch 缓存清理
torch.cuda.empty_cache()
智能的内存使用监控
vLLM 实现了内存使用监控,动态调整行为:
class MemoryMonitor:
def __init__(self, device, warning_threshold=0.9, critical_threshold=0.95):
self.device = device
self.warning_threshold = warning_threshold
self.critical_threshold = critical_threshold
self.last_check_time = 0
self.check_interval = 1.0 # 秒
def check_memory(self):
"""检查内存使用情况并作出响应"""
current_time = time.time()
if current_time - self.last_check_time < self.check_interval:
return MemoryStatus.OK
# 更新检查时间
self.last_check_time = current_time
# 获取当前内存使用
used_memory = torch.cuda.memory_allocated(self.device)
total_memory = torch.cuda.get_device_properties(self.device).total_memory
memory_fraction = used_memory / total_memory
# 根据使用率确定状态
if memory_fraction > self.critical_threshold:
return MemoryStatus.CRITICAL
elif memory_fraction > self.warning_threshold:
return MemoryStatus.WARNING
else:
return MemoryStatus.OK
def get_recommended_actions(self, status):
"""根据内存状态提供建议操作"""
if status == MemoryStatus.CRITICAL:
return [
"swap_out_inactive_sequences",
"reduce_batch_size",
"force_garbage_collect"
]
elif status == MemoryStatus.WARNING:
return [
"delay_new_requests",
"compress_kv_cache"
]
else:
return []
这个监控器与调度器集成,动态调整系统行为:
def adaptive_sequence_scheduling(self):
"""根据内存使用自适应调整调度"""
# 检查内存状态
memory_status = self.memory_monitor.check_memory()
actions = self.memory_monitor.get_recommended_actions(memory_status)
# 应用推荐操作
if "reduce_batch_size" in actions:
# 临时降低批大小
self.current_max_batch_size = max(1, self.max_batch_size // 2)
else:
# 恢复正常批大小
self.current_max_batch_size = self.max_batch_size
if "swap_out_inactive_sequences" in actions:
# 交换出不活跃序列
inactive_seqs = self._identify_inactive_sequences()
for seq_id in inactive_seqs:
self.swap_out_sequence(seq_id)
if "force_garbage_collect" in actions:
# 强制垃圾回收
torch.cuda.empty_cache()
gc.collect()
实际应用案例与性能收益
通过这些内存优化策略的组合应用,vLLM 在实际部署中取得了显著的性能改进:
- 并发能力提升:
# 应用优化前(传统方法) max_concurrent_requests = 5 # 13B 模型,A100 GPU # 应用优化后(vLLM) max_concurrent_requests = 20 # 同样配置下增加4倍 - 内存效率提升:
# 传统部署(静态批处理) memory_per_request = 8 * hidden_size * max_seq_len * num_layers # vLLM(分页注意力+内存优化) memory_per_request = 8 * hidden_size * actual_seq_len * num_layers / efficiency_factor # efficiency_factor ≈ 2.5-3.0 - 量化效益:
# FP16 模型 model_size_gb = 13 # 对于13B模型 # INT8 量化后 model_size_gb = 6.5 # 节省50%内存 # INT4 量化后 model_size_gb = 3.25 # 节省75%内存
总的来说,vLLM 的内存优化策略在多个层面协同工作,从模型权重优化、中间激活管理到 KV 缓存组织,全方位提升了大型语言模型的推理效率。这使得在单个 GPU 上可以部署更大的模型或服务更多的并发用户,大幅降低了 LLM 服务的硬件需求和运营成本。
5.6 并行计算优化
vLLM 实现了多种并行计算优化策略,提高服务性能和并发能力。这些策略从不同层面优化计算效率,减少资源消耗,提高服务质量。
并行计算的基本原理
并行计算的核心思想是将一个任务分解为多个子任务,并在多个处理器上同时执行这些子任务。vLLM 通过以下几种方式实现并行计算:
- 多线程:利用操作系统提供的线程机制,在单个进程中同时执行多个线程。
- 多进程:利用操作系统提供的进程机制,在单个机器上同时运行多个进程。
- 分布式计算:利用网络通信机制,在多台机器上同时执行计算任务。
vLLM 的并行计算策略包括:
- 线程池:预先创建一组线程,用于处理并发请求。
- 进程池:预先创建一组进程,用于处理并发请求。
- 分布式调度:利用分布式计算框架(如 Ray)实现任务调度。
线程池与进程池
vLLM 实现了线程池和进程池机制,用于管理并发线程和进程。这些机制可以显著提高服务性能,减少线程切换和进程切换的开销。
# 线程池示例
thread_pool = ThreadPool(max_workers=10)
# 进程池示例
process_pool = Pool(processes=4)
分布式调度
vLLM 利用分布式计算框架(如 Ray)实现分布式调度,将任务分配到多个处理器上执行。分布式调度可以显著提高服务性能,减少单点故障的风险。
# Ray 示例
from ray import serve
@serve.deployment
class MyModel:
def __call__(self, request):
# 分布式任务调度
result = ray.get(ray.remote(compute_task)(request))
return result
实际应用案例
在 vLLM 中,并行计算优化策略的应用如下:
- 线程池:在每次前向传播中创建多个线程,用于处理并发请求。
# 线程池示例 thread_pool = ThreadPool(max_workers=10) # 在每次前向传播中创建线程 def execute_model(self, input_ids, positions, kv_caches, block_tables): # 创建线程池 with ThreadPoolExecutor(max_workers=10) as executor: futures = [executor.submit(self._forward_helper, input_ids, positions, kv_caches, block_tables) for _ in range(10)] results = [future.result() for future in futures] return results - 进程池:在每次前向传播中创建多个进程,用于处理并发请求。
# 进程池示例 process_pool = Pool(processes=4) # 在每次前向传播中创建进程 def execute_model(self, input_ids, positions, kv_caches, block_tables): # 创建进程池 with Pool(processes=4) as pool: results = pool.map(self._forward_helper, [input_ids] * 4, [positions] * 4, [kv_caches] * 4, [block_tables] * 4) return results - 分布式调度:利用分布式计算框架(如 Ray)实现分布式调度,将任务分配到多个处理器上执行。
# Ray 示例 from ray import serve @serve.deployment class MyModel: def __call__(self, request): # 分布式任务调度 result = ray.get(ray.remote(compute_task)(request)) return result
总的来说,vLLM 的并行计算优化策略显著提高了服务性能和并发能力,减少了资源消耗,提高了服务质量。这些策略从不同层面优化计算效率,减少线程切换和进程切换的开销,同时提高了系统的稳定性和可靠性。
5. 架构与类关系图
5.1 整体架构概览
vLLM的架构设计采用了模块化和层次化的方式,清晰分离了不同功能组件,使系统具有高度的可扩展性和可维护性。下图展示了vLLM的整体架构:
+---------------------+
| 用户 API 层 | (LLM, AsyncLLM 接口)
+----------+----------+
|
+----------v----------+
| LLMEngine 层 | (核心协调器)
+----------+----------+
|
+-----+-----+
| |
+----v----+ +----v----+
|Scheduler| |Worker池 | (调度与执行)
+----+----+ +----+----+
| |
| +----v----+
| |Model | (模型执行)
| |Runner |
| +----+----+
| |
+----v----+ +----v----+
|请求队列 | |BlockMgr | (资源管理)
+----+----+ +----+----+
| |
+----v-----------v----+
| 底层优化层 | (CUDA图, KV缓存)
+---------------------+
5.2 核心类结构图
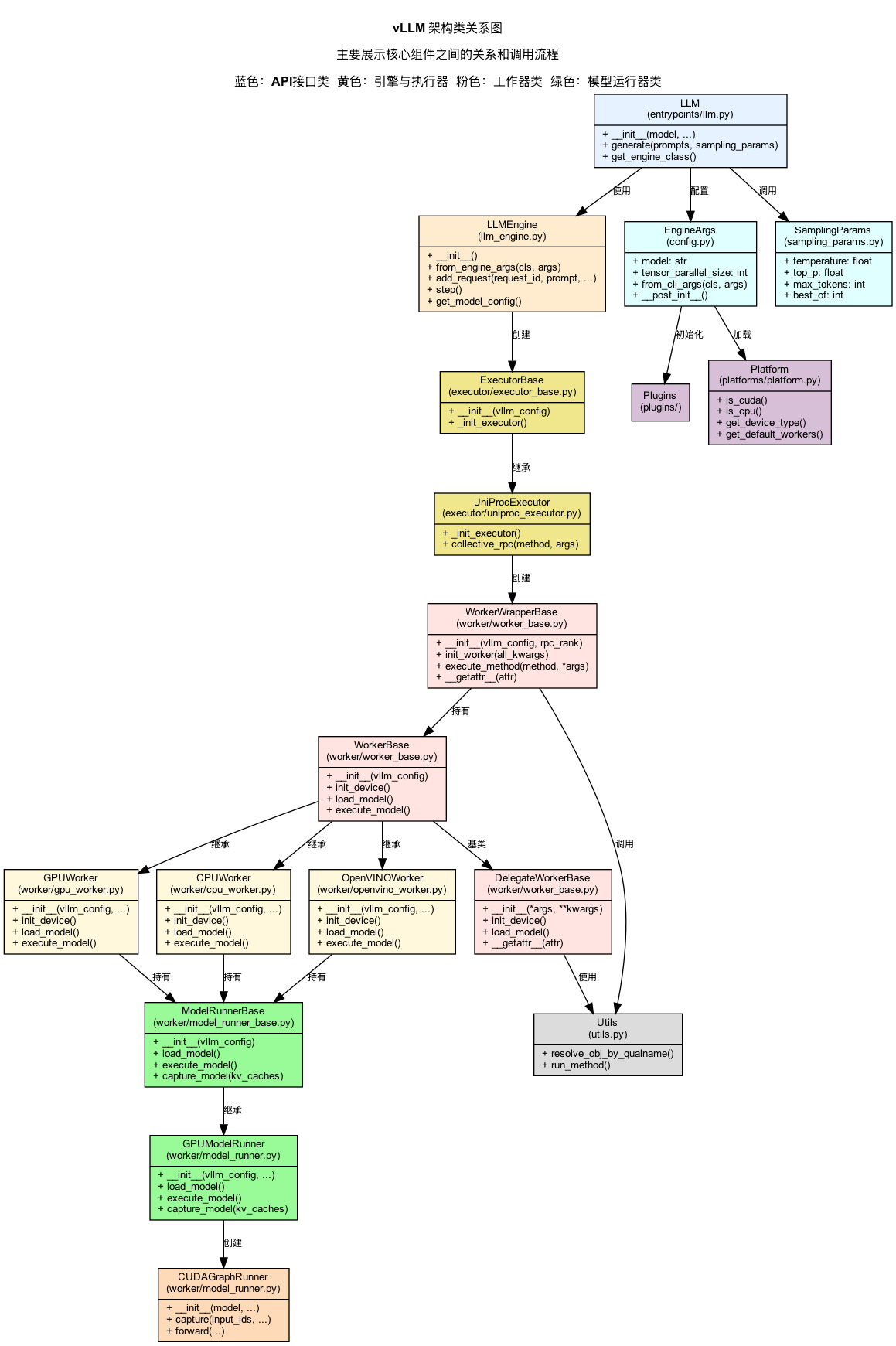
vLLM的主要类及其关系如下:
LLMEngine
├── ModelConfig // 模型配置
├── ParallelConfig // 并行策略配置
├── SchedulerConfig // 调度器配置
├── CacheConfig // 缓存配置
│
├── Tokenizer // 分词器
├── RequestTracker // 请求跟踪器
│ └── Request // 请求对象
│
├── Scheduler[] // 调度器数组
│ ├── SequenceGroup // 序列组
│ └── Sequence // 序列
│
└── WorkerPool // Worker池
├── Worker // Worker实例
│ ├── ModelRunner // 模型执行器
│ │ ├── AttentionState // 注意力状态
│ │ └── CUDAGraphRunner // CUDA图执行器
│ │
│ └── BlockSpaceManager // 块空间管理器
│ ├── BlockAllocator // 块分配器
│ └── BlockTable // 块表
│
└── ModelReplica // 模型副本
5.3 关键组件交互流程
vLLM的核心交互流程如下图所示,展示了请求从接收到处理完成的整个生命周期:
Client → [LLM API] → LLMEngine.add_request()
│ │
│ ▼
│ RequestTracker
│ │
│ ▼
│ Scheduler.add_request()
│ │
│ ▼
│ Engine Core Loop
│ │
│ ▼
│ Scheduler.schedule()
│ │
│ ▼
│ Worker.execute_model()
│ │
│ ▼
│ ModelRunner.forward()
│ │
│ ▼
Client ← [Results] ← Engine._process_outputs()
5.4 并行与分布式架构
vLLM支持多种并行策略,包括张量并行、流水线并行和数据并行:
数据并行 (多副本)
+----------+ +----------+
| Engine 1 | | Engine 2 |
+-----+----+ +----+-----+
| |
+-----v----+ +----v-----+
| Model 1 | | Model 2 |
+----------+ +----------+
张量并行 (单模型分片)
+-------------------+
| Engine |
+---------+---------+
|
+---------v---------+
| 分布式模型 (TP=2) |
+---+-------------+-+
| |
+---v---+ +---v---+
|GPU 0 | |GPU 1 |
|模型分片| |模型分片|
+-------+ +-------+
5.5 内存管理架构
vLLM的PagedAttention内存管理模型:
序列1 序列2 序列3 ← 逻辑序列
↓ ↓ ↓
+---+ +---+ +---+
| A | | C | | E | ← 块表
+---+ +---+ +---+
↓ ↓ ↓
+---+ +---+ +---+
| 1 | | 3 | | 5 | ← 物理块索引
+---+ +---+ +---+
↓ ↓ ↓
+---+ +---+ +---+
| B | | D | | F | ← 块表
+---+ +---+ +---+
↓ ↓ ↓
+---+ +---+ +---+
| 2 | | 4 | | 6 | ← 物理块索引
+---+ +---+ +---+
物理内存:
+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 | ← 物理块
+---+---+---+---+---+---+
这种分页架构允许高效利用GPU内存,使不同长度的序列能够共享物理内存,大幅提升内存利用率。
6. 高级 Python 语法应用
vLLM 代码中应用了多种高级 Python 语法特性,这些特性提高了代码的灵活性、可维护性和性能。即使你不熟悉vLLM,理解这些Python高级特性也能帮助你写出更好的代码。
6.1 类型注解与泛型编程
vLLM 广泛使用类型注解提高代码可读性和健壮性:
# 类型变量的使用
ModelRunnerClass: Type[GPUModelRunnerBase] = ModelRunner
这种语法表示 ModelRunnerClass 是一个类型变量,它指向的类必须是 GPUModelRunnerBase 的子类。这不仅提供了类型安全性,还使代码更加自解释。
类型注解的优势:
- 提供更好的 IDE 支持和自动补全
- 在编译时捕获类型错误
- 使接口约束更明确
- 支持泛型编程模式
vLLM 中常见的类型注解模式:
from typing import Dict, List, Optional, Tuple, Union, Type, TypeVar, Generic
# 基本类型注解
def process_tokens(tokens: List[int]) -> List[str]:
"""处理token IDs并返回字符串列表"""
return [str(token) for token in tokens]
# 泛型和类型变量
T = TypeVar('T', bound=BaseModel)
class Registry(Generic[T]):
"""通用模型注册表"""
def __init__(self):
self.models: Dict[str, T] = {}
def register(self, model: T) -> None:
self.models[model.name] = model
def get(self, name: str) -> Optional[T]:
return self.models.get(name)
# 可选类型
def get_cache(key: str) -> Optional[torch.Tensor]:
"""从缓存获取张量,可能返回None"""
if key in cache:
return cache[key]
return None
# 联合类型
def process_input(input_data: Union[str, List[str], Dict[str, str]]) -> None:
"""处理多种可能的输入类型"""
if isinstance(input_data, str):
# 处理单个字符串
pass
elif isinstance(input_data, list):
# 处理字符串列表
pass
else:
# 处理字典
pass
在vLLM核心组件如引擎和调度器中,类型注解扮演着关键角色。例如,引擎的参数定义:
class EngineArgs:
"""引擎参数配置"""
def __init__(
self,
model: str,
tokenizer: Optional[str] = None,
tensor_parallel_size: int = 1,
dtype: Optional[str] = None,
quantization: Optional[str] = None,
revision: Optional[str] = None,
tokenizer_revision: Optional[str] = None,
seed: int = 0,
max_model_len: Optional[int] = None,
worker_use_ray: bool = False,
pipeline_parallel_size: int = 1,
block_size: int = 16,
swap_space: int = 4,
gpu_memory_utilization: float = 0.9,
max_num_batched_tokens: Optional[int] = None,
max_num_seqs: int = 256,
max_paddings: int = 256,
disable_log_stats: bool = False,
revision_date: Optional[str] = None,
tokenizer_mode: str = "auto",
trust_remote_code: bool = False,
max_log_len: Optional[int] = None,
tokenizer_timeout_s: int = 60,
) -> None:
...
这种详细的类型注解使得参数含义一目了然,同时也在运行时提供类型检查。通过 mypy 等静态类型检查工具,可以在代码运行前发现潜在的类型错误。
在工作原理上,Python 的类型注解是通过 PEP 484、PEP 526 等规范实现的,允许开发者在代码中标注变量、参数和返回值的类型。这些注解在运行时不会强制执行类型检查,但它们可以被 IDE 和静态分析工具使用。
vLLM 项目通过严格的类型注解,显著提高了代码质量和开发效率,特别是在处理复杂的并行计算和内存管理时,类型安全对于避免潜在错误至关重要。
6.2 动态类解析与反射机制
vLLM 使用 Python 的反射机制实现动态类加载和实例化,这对于构建灵活的架构至关重要:
def resolve_class_by_name(class_name: str) -> Type:
"""根据完全限定名解析类"""
module_name, class_name = class_name.rsplit(".", 1)
module = importlib.import_module(module_name)
return getattr(module, class_name)
# 使用示例
worker_class_name = config.get("worker_class", "vllm.worker.Worker")
worker_class = resolve_class_by_name(worker_class_name)
worker = worker_class(**worker_args)
这种动态加载机制的关键实现细节:
- 模块导入:使用
importlib.import_module在运行时导入模块 - 属性获取:使用
getattr动态获取模块中的类或函数 - 运行时实例化:根据字符串配置动态创建类实例
在 vLLM 中,这种机制广泛应用于多个组件:
# 在 worker.py 中动态加载模型实现
def _initialize_worker(model_config):
model_type = model_config.model_type
if model_type == "gpt_neox":
model_cls_name = "vllm.model.GPTNeoXForCausalLM"
elif model_type == "llama":
model_cls_name = "vllm.model.LlamaForCausalLM"
elif model_type == "mistral":
model_cls_name = "vllm.model.MistralForCausalLM"
else:
# 支持完全自定义模型
model_cls_name = model_config.get("model_class")
# 动态加载模型类
model_cls = resolve_class_by_name(model_cls_name)
return model_cls(model_config)
vLLM 的执行器系统也依赖于动态类解析:
def get_executor(args: EngineArgs) -> ExecutorBase:
"""根据配置创建合适的执行器"""
if args.distributed_executor_backend:
# 根据配置选择不同的分布式执行器
if args.distributed_executor_backend == "ray":
executor_cls_name = "vllm.executor.RayExecutor"
elif args.distributed_executor_backend == "mp":
executor_cls_name = "vllm.executor.MultiprocessingExecutor"
else:
executor_cls_name = args.distributed_executor_backend
# 动态加载执行器类
executor_cls = resolve_class_by_name(executor_cls_name)
return executor_cls(args)
else:
# 默认使用本地执行器
return LocalExecutor(args)
除了类加载,vLLM 还使用反射来实现参数检查和默认值处理:
def create_engine_from_args(args_dict: Dict[str, Any]) -> LLMEngine:
"""从字典创建引擎实例"""
# 获取 EngineArgs 的签名
sig = inspect.signature(EngineArgs.__init__)
# 过滤有效参数
valid_params = {}
for param_name, param in sig.parameters.items():
if param_name in args_dict:
valid_params[param_name] = args_dict[param_name]
# 创建 EngineArgs 实例
engine_args = EngineArgs(**valid_params)
# 创建引擎
return LLMEngine.from_engine_args(engine_args)
这种动态类解析与反射机制的优势:
- 插件架构支持:允许不修改核心代码的情况下扩展功能
- 配置驱动的组件加载:通过配置文件或环境变量控制实现细节
- 避免硬编码依赖:降低组件间耦合,提高代码可维护性
- 运行时组件替换:支持根据环境和需求动态选择最佳实现
作为一个具体例子,用户可以通过配置指定一个自定义的调度器类:
# 用户代码
custom_args = {
"model": "llama-3.2-1b-instruct",
"scheduler_class": "my_project.schedulers.CustomPriorityScheduler"
}
engine = create_engine_from_args(custom_args)
内部实现会动态加载用户提供的调度器类并使用它,而不需要修改 vLLM 的核心代码。这种灵活性使 vLLM 能够适应各种特定需求,同时保持核心代码的稳定性。
总的来说,动态类解析和反射机制是 vLLM 灵活架构的关键,它使得系统能够根据需求动态加载不同组件,适应不同的硬件环境和使用场景。
6.3 方法委托与魔术方法
vLLM 使用 __getattr__ 魔术方法实现方法委托,这是一种强大的设计模式:
class WorkerWrapperBase:
def __init__(self, worker):
self.worker = worker
def __getattr__(self, attr):
return getattr(self.worker, attr)
这段看似简单的代码实际上实现了一个强大的代理模式。当在 WorkerWrapperBase 实例上访问一个不存在的属性或方法时,Python 会调用 __getattr__ 方法。这个方法将请求委托给内部的 worker 对象,实现了透明的方法转发。
具体工作流程:
- 客户代码调用
worker_wrapper.some_method() - 如果
worker_wrapper没有some_method属性,Python 调用__getattr__('some_method') __getattr__返回worker.some_method- 客户代码实际调用了
worker.some_method()
在 vLLM 中,这种模式的应用场景:
# 在 executor.py 中
class LocalExecutor(ExecutorBase):
def __init__(self, args):
# 创建本地 Worker
self.worker = Worker(...)
def __getattr__(self, attr):
# 将方法调用委托给内部 Worker
return getattr(self.worker, attr)
# 在 engine.py 中
def init_device(self):
# LocalExecutor 没有 init_device 方法,但这个调用会被委托给内部的 worker
self.executor.init_device()
另一个例子是 vLLM 的 DelegateWorkerBase 类:
class DelegateWorkerBase(WorkerBase):
def __init__(self, worker: WorkerBase):
self.worker = worker
def __getattr__(self, attr):
return getattr(self.worker, attr)
这种设计模式的优势:
- 代码减少:不需要为每个要转发的方法编写样板代码
- 透明代理:客户代码无需了解委托机制
- 动态性:支持运行时添加的方法,无需修改代理类
- 装饰器模式:可以轻松在方法调用前后添加额外行为
例如,添加日志记录功能:
class LoggingWorkerWrapper(WorkerWrapperBase):
def __getattr__(self, attr):
original_attr = super().__getattr__(attr)
if callable(original_attr):
def wrapper(*args, **kwargs):
logger.debug(f"Calling {attr} with args: {args}, kwargs: {kwargs}")
result = original_attr(*args, **kwargs)
logger.debug(f"{attr} returned: {result}")
return result
return wrapper
return original_attr
在 vLLM 中,这种方法委托模式解决了一个关键问题:WorkerBase 定义了许多抽象方法,如 init_device 和 load_model,这些方法在子类中必须实现。通过方法委托,可以创建特殊的 Worker 包装器,而不必实现所有抽象方法,只需将它们委托给内部的 Worker 实例。
# 抽象基类定义
class WorkerBase:
def init_device(self):
raise NotImplementedError
def load_model(self):
raise NotImplementedError
# 具体实现
class CUDAWorker(WorkerBase):
def init_device(self):
# CUDA 实现
...
def load_model(self):
# CUDA 模型加载
...
# 代理类 - 无需实现抽象方法
class MonitoringWorker(WorkerBase):
def __init__(self, worker: WorkerBase):
self.worker = worker
self.metrics = {}
def __getattr__(self, attr):
return getattr(self.worker, attr)
# 只添加新功能,无需重新实现所有方法
def collect_metrics(self):
# 收集性能指标
...
通过魔术方法实现的方法委托是 vLLM 灵活架构的关键组成部分,它减少了代码重复,提高了组件间的解耦性,并使系统更容易扩展。
6.4 弱引用与特殊调用模式
vLLM 在处理对象引用时使用了 weakref.proxy,特别是在注意力状态初始化中:
class ModelRunner:
def initialize_attention_state(self):
# 创建注意力状态类的实例
self.attn_state = self.attn_backend.get_state_cls()(weakref.proxy(self))
这行代码结合了三种高级 Python 特性:
- 动态类获取:
get_state_cls()返回类定义而非实例 - 弱引用:
weakref.proxy(self)创建对象的弱引用 - 链式调用:立即实例化获取的类
让我们详细分析这些特性:
动态类获取
get_state_cls() 方法返回一个类定义,而不是类的实例:
def get_state_cls(self):
"""返回适用于当前后端的注意力状态类"""
if self.use_flash_attention:
return FlashAttentionState
elif self.use_varlen_attention:
return VarLenAttentionState
else:
return StandardAttentionState
这种工厂方法模式允许系统根据运行时条件选择适当的实现。
弱引用与 weakref.proxy
weakref.proxy(self) 创建了一个代理对象,它的行为类似于对原始对象的引用,但不增加引用计数:
# 常规引用
runner = ModelRunner()
state = AttentionState(runner) # runner 的引用计数加 1
# 弱引用
runner = ModelRunner()
state = AttentionState(weakref.proxy(runner)) # runner 的引用计数不变
弱引用的主要优势:
- 避免循环引用:
ModelRunner包含attn_state,而attn_state需要引用回ModelRunner。如果使用普通引用,会形成循环引用,导致内存泄漏。 - 不阻止垃圾回收:当所有普通引用消失时,对象可以被回收,即使仍有弱引用。
- 自动失效:当被引用对象被回收时,weakref.proxy 会抛出 ReferenceError,而不是悄悄返回陈旧数据。
在大型模型处理中,内存管理是核心挑战,弱引用帮助 vLLM 管理复杂的对象关系,避免不必要的内存消耗。
链式调用模式
链式调用是将多个操作组合成一行代码的技术:
# 拆分写法
cls = self.attn_backend.get_state_cls()
self.attn_state = cls(weakref.proxy(self))
# 链式写法
self.attn_state = self.attn_backend.get_state_cls()(weakref.proxy(self))
这种模式提高了代码简洁性,减少了中间变量,同时保持了可读性。
实际应用案例
在 vLLM 中,注意力状态类需要访问 ModelRunner 的方法和属性,但同时 ModelRunner 也需要持有注意力状态实例。这是一个典型的循环引用场景:
class AttentionState:
def __init__(self, model_runner):
self.model_runner = model_runner
def compute_attention(self, query):
# 访问 model_runner 的属性和方法
batch_size = self.model_runner.batch_size
...
class ModelRunner:
def initialize(self):
# 创建并持有注意力状态
self.attn_state = AttentionState(self) # 直接引用会造成循环引用
使用弱引用解决这个问题:
class AttentionState:
def __init__(self, model_runner):
# 使用弱引用避免循环引用
self.model_runner = weakref.proxy(model_runner)
class ModelRunner:
def initialize(self):
# 安全地创建注意力状态
self.attn_state = AttentionState(self)
这种模式在大型模型中特别重要,因为这些模型处理大量内存,任何内存泄漏都可能导致严重问题。
此外,vLLM 还在缓存管理和事件回调系统中使用了弱引用:
class CacheManager:
def __init__(self):
# 使用 WeakValueDictionary 避免阻止对象回收
self.cache = weakref.WeakValueDictionary()
def add_to_cache(self, key, value):
self.cache[key] = value
def get_from_cache(self, key):
return self.cache.get(key)
总结起来,vLLM 通过组合动态类获取、弱引用和链式调用,实现了高效、灵活且内存安全的对象交互模式,这对于管理大型语言模型的复杂组件关系至关重要。
6.5 类方法与工厂模式
vLLM 使用类方法实现工厂模式,这是一种创建对象的优雅方式:
class LLMEngine:
@classmethod
def from_engine_args(cls, args: EngineArgs) -> "LLMEngine":
# 创建并配置引擎实例
engine = cls()
executor = get_executor(args)
executor.init_workers(args)
executor.init_device()
executor.load_model()
return engine
类方法与普通方法和静态方法的区别在于它接收类本身作为第一个参数(通常命名为 cls),而不是实例(self)。这使得类方法可以访问和操作类级别的属性和方法,同时也能创建类的实例。
工厂模式实现
在 vLLM 中,类方法作为工厂函数非常常见:
class ModelLoader:
@classmethod
def from_pretrained(cls, model_path: str, **kwargs) -> "ModelLoader":
# 1. 检查模型类型
model_type = cls._detect_model_type(model_path)
# 2. 加载配置
config = cls._load_config(model_path, model_type)
# 3. 准备参数
params = {**config, **kwargs}
# 4. 创建适当的实例
return cls(params)
这种方法的优势包括:
- 封装实例化逻辑:隐藏复杂的创建过程
- 提供友好的接口:比直接调用构造函数更易用
- 支持多态:子类可以重写和扩展工厂方法
- 预处理参数:在创建实例前验证和准备参数
多态行为
类方法与继承配合使用时特别强大:
class BaseScheduler:
@classmethod
def create(cls, config: Dict[str, Any]) -> "BaseScheduler":
return cls(config)
class FIFOScheduler(BaseScheduler):
pass
class PriorityScheduler(BaseScheduler):
@classmethod
def create(cls, config: Dict[str, Any]) -> "PriorityScheduler":
# 特殊处理优先级配置
if "priorities" not in config:
config["priorities"] = {"default": 1}
return super().create(config)
# 使用示例
schedulers = {
"fifo": FIFOScheduler,
"priority": PriorityScheduler
}
# 动态选择调度器类型
scheduler_cls = schedulers[config.scheduler_type]
# 调用类方法创建实例
scheduler = scheduler_cls.create(config)
在这个例子中,create 类方法在 BaseScheduler 中定义,但 PriorityScheduler 重写了它以提供特定的行为。调用子类的 create 方法时会执行子类的逻辑,然后通过 super().create() 调用父类的实现。
与单例模式结合
vLLM 还将类方法与单例模式结合,确保某些组件只有一个实例:
class TokenizerManager:
_instances = {}
@classmethod
def get_tokenizer(cls, model_name: str) -> "Tokenizer":
"""获取或创建对应模型的分词器"""
if model_name not in cls._instances:
# 创建新的分词器实例
cls._instances[model_name] = cls._load_tokenizer(model_name)
# 返回缓存的实例
return cls._instances[model_name]
@classmethod
def _load_tokenizer(cls, model_name: str) -> "Tokenizer":
"""加载特定模型的分词器"""
# 实现分词器加载逻辑
...
这种模式确保了资源密集型组件(如分词器)在多次请求时只加载一次,提高了性能和内存效率。
静态方法对比
vLLM 同时使用了静态方法和类方法,它们的区别在于:
class Utility:
# 静态方法 - 不访问类或实例
@staticmethod
def format_tensor(tensor):
# 纯功能逻辑,不依赖类状态
return tensor.to(dtype=torch.float16)
# 类方法 - 访问类但不访问实例
@classmethod
def create_default(cls):
# 可以访问类并创建实例
return cls()
当方法需要访问类本身(如创建实例或访问类变量)时,使用类方法;当方法只是逻辑上与类相关但不需要访问类或实例状态时,使用静态方法。
实际应用案例
在 vLLM 的 LLMEngine 中,类方法用于提供多种创建实例的方式:
class LLMEngine:
@classmethod
def from_engine_args(cls, args: EngineArgs) -> "LLMEngine":
# 从标准参数创建
...
@classmethod
def from_checkpoint(cls, checkpoint_path: str) -> "LLMEngine":
# 从检查点恢复
checkpoint = torch.load(checkpoint_path)
engine = cls()
engine.load_state_dict(checkpoint["engine_state"])
return engine
@classmethod
def from_pretrained(cls, model_name: str) -> "LLMEngine":
# 从预训练模型创建
args = EngineArgs(model=model_name)
return cls.from_engine_args(args)
这种方式提供了灵活的创建选项,同时保持了接口的一致性和可读性。
总的来说,vLLM 中的类方法和工厂模式是构建灵活且可扩展系统的关键组成部分,它们简化了对象创建,支持多态行为,并提供了清晰的接口供用户使用。
6.6 装饰器高级应用
vLLM 使用多种装饰器增强函数和类的功能,既利用了标准库提供的装饰器,也实现了自定义装饰器:
# 推理模式装饰器
@torch.inference_mode()
def forward(self, *args, **kwargs):
# 在推理模式下执行,禁用梯度计算
return self.model(*args, **kwargs)
# 性能分析装饰器
@profile_function
def execute_model(self, batch):
# 执行并记录性能数据
return self.model_runner(batch)
# 自定义警告装饰器
@warn_for_unimplemented_methods
class WorkerBase:
# 抽象基类
def init_device(self):
raise NotImplementedError
装饰器是 Python 的强大特性,可以在不修改原始函数定义的情况下添加功能。它们在 vLLM 中被用于多种用途。
torch.inference_mode() 装饰器
torch.inference_mode() 是 PyTorch 提供的性能优化装饰器,类似于 torch.no_grad(),但进一步优化:
@torch.inference_mode()
def capture_model(self, kv_caches: List[List[torch.Tensor]]) -> None:
"""捕获 CUDA 图以加速推理"""
# 在此函数中执行的所有 PyTorch 操作都在推理模式下
# 这会禁用梯度计算,减少内存使用,提高速度
...
在推理模式下,PyTorch 会:
- 禁用梯度跟踪和计算
- 跳过不必要的内存分配
- 启用其他优化
对于 vLLM 这种专注于推理的框架来说,这种优化至关重要。
自定义性能分析装饰器
vLLM 实现了自定义装饰器来分析关键函数的性能:
def profile_function(func):
"""记录函数执行时间的装饰器"""
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
elapsed_time = time.time() - start_time
# 记录性能数据
function_name = func.__name__
logger.debug(f"{function_name} took {elapsed_time:.6f} seconds")
# 更新性能指标
metrics = get_metrics_singleton()
metrics.update(function_name, elapsed_time)
return result
return wrapper
这个装饰器用于包装关键函数,记录它们的执行时间,帮助开发人员识别性能瓶颈。@functools.wraps(func) 确保包装函数保留原始函数的元数据(如名称和文档字符串)。
方法检查装饰器
vLLM 使用装饰器来验证子类是否正确实现了抽象方法:
def warn_for_unimplemented_methods(cls):
"""装饰抽象基类,警告未实现的方法"""
original_init = cls.__init__
@functools.wraps(original_init)
def new_init(self, *args, **kwargs):
# 调用原始 __init__
original_init(self, *args, **kwargs)
# 检查是否实现了所有抽象方法
for name, method in inspect.getmembers(cls, inspect.isfunction):
if getattr(method, "_is_abstract", False):
# 获取实际实例的方法
instance_method = getattr(self.__class__, name)
# 检查是否仍然是抽象方法
if getattr(instance_method, "_is_abstract", False):
logger.warning(
f"Class {self.__class__.__name__} does not implement "
f"abstract method {name} from {cls.__name__}"
)
# 替换 __init__ 方法
cls.__init__ = new_init
return cls
这个类装饰器修改了目标类的 __init__ 方法,在初始化时检查子类是否实现了所有标记为抽象的方法,并发出警告。
上下文管理器装饰器
vLLM 使用 contextlib.contextmanager 装饰器创建上下文管理器:
@contextlib.contextmanager
def graph_capture(device: torch.device):
"""CUDA 图捕获上下文管理器"""
# 设置环境
torch.cuda.synchronize(device)
stream = torch.cuda.Stream(device)
stream.synchronize()
# 获取初始内存状态
start_free_gpu_memory = torch.cuda.mem_get_info(device)[0]
with torch.cuda.stream(stream):
try:
# 进入上下文
yield {"stream": stream}
finally:
# 退出上下文
stream.synchronize()
torch.cuda.synchronize(device)
# 记录内存使用
end_free_gpu_memory = torch.cuda.mem_get_info(device)[0]
memory_used = start_free_gpu_memory - end_free_gpu_memory
这个装饰器将函数转换为上下文管理器,可以通过 with 语句使用,确保资源的正确分配和释放。
缓存装饰器
vLLM 实现了结果缓存装饰器,用于优化重复计算:
def cache_result(max_size: int = 128):
"""缓存函数结果的装饰器"""
cache = {}
order = []
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 创建缓存键
key = (args, frozenset(kwargs.items()))
# 检查缓存
if key in cache:
# 缓存命中,更新使用顺序
order.remove(key)
order.append(key)
return cache[key]
# 缓存未命中,调用原始函数
result = func(*args, **kwargs)
# 更新缓存
cache[key] = result
order.append(key)
# 如果缓存过大,删除最老的项
if len(cache) > max_size:
oldest_key = order.pop(0)
del cache[oldest_key]
return result
return wrapper
return decorator
这个装饰器实现了一个简单的 LRU 缓存,可以避免重复计算昂贵的函数调用,特别是对于分词等操作。
组合装饰器
vLLM 经常将多个装饰器组合使用,叠加它们的功能:
# 组合多个装饰器
@torch.inference_mode()
@profile_function
@retry_on_cuda_oom
def forward(self, *args, **kwargs):
# 函数体
...
装饰器的应用顺序是从下到上的,即:
- 首先应用
@retry_on_cuda_oom - 然后应用
@profile_function - 最后应用
@torch.inference_mode()
这种组合可以同时提供多种功能增强,如性能优化、错误恢复和执行分析。
总的来说,装饰器在 vLLM 中扮演着重要角色,提供了代码重用、关注点分离和功能增强的优雅方式。它们使得代码更加简洁、可维护,并便于实现横切关注点,如性能分析、错误处理和资源管理。
6.7 上下文管理与多重上下文
vLLM 使用上下文管理器进行资源管理和状态控制,一个典型示例是 CUDA 图捕获过程:
def capture_model(self, kv_caches):
# 多重嵌套上下文管理器
with self.attn_state.graph_capture(max_batch_size), \
graph_capture(self.device) as graph_capture_context, \
set_forward_context(attn_metadata, self.config, virtual_engine):
# 执行图捕获
graph_runner.capture(**capture_inputs)
上下文管理器(通过 with 语句使用)提供了一种优雅的方式来管理资源和状态,确保在代码块执行前后正确地设置和清理环境。
多重嵌套上下文
vLLM 经常使用多重嵌套的上下文管理器来处理复杂的环境设置:
def _execute_with_graphs(self, *args, **kwargs):
"""使用 CUDA 图执行的函数"""
# 1. 设置流和事件
with torch.cuda.stream(self.capture_stream):
# 2. 设置记录状态
with cuda_profiler.record("cuda_graph_execution"):
# 3. 设置环境标记
with set_sync_free_context():
# 执行图
self.graph.replay()
# 等待图执行完成
self.capture_stream.synchronize()
这种嵌套模式确保了正确的资源管理和状态设置顺序,每个上下文都有其特定的职责。
资源管理上下文
vLLM 使用上下文管理器来处理资源分配和释放:
@contextlib.contextmanager
def cuda_memory_context():
"""管理临时 CUDA 内存分配的上下文"""
# 记录初始内存状态
initial_allocated = torch.cuda.memory_allocated()
try:
# 提供上下文
yield
finally:
# 主动释放未使用的缓存内存
torch.cuda.empty_cache()
# 验证内存是否正确释放
final_allocated = torch.cuda.memory_allocated()
if final_allocated > initial_allocated:
logger.warning(
f"Memory leak detected: {final_allocated - initial_allocated} bytes"
)
这个上下文管理器跟踪 CUDA 内存分配,确保在上下文退出时释放未使用的内存,并警告可能的内存泄漏。
状态设置上下文
vLLM 使用上下文管理器来临时修改系统状态:
@contextlib.contextmanager
def set_sync_free_context():
"""设置同步不受限的环境"""
# 保存原始状态
original_flag = torch.backends.cuda.matmul.allow_tf32
# 修改状态
torch.backends.cuda.matmul.allow_tf32 = True
try:
# 提供上下文
yield
finally:
# 恢复原始状态
torch.backends.cuda.matmul.allow_tf32 = original_flag
这个上下文管理器临时启用 TF32 数学运算,提高性能,并在退出时恢复原始设置。
异常处理上下文
vLLM 使用上下文管理器来实现更好的异常处理:
@contextlib.contextmanager
def catch_oom_error():
"""捕获并处理 CUDA 内存不足错误"""
try:
yield
except torch.cuda.OutOfMemoryError as e:
# 清理缓存
torch.cuda.empty_cache()
# 记录错误
logger.error("CUDA out of memory. Attempting recovery.")
# 转换为自定义异常
raise CudaOutOfMemoryError("GPU memory exceeded") from e
这个上下文管理器捕获 CUDA 内存不足错误,尝试清理内存,并转换为自定义异常以便更好地处理。
自定义上下文管理器类
除了使用 @contextlib.contextmanager 装饰器,vLLM 还实现了自定义上下文管理器类:
class GraphContext:
"""CUDA 图捕获和执行的上下文管理器"""
def __init__(self, device, stream=None):
self.device = device
self.stream = stream or torch.cuda.Stream(device)
self.original_stream = None
def __enter__(self):
# 保存当前流
self.original_stream = torch.cuda.current_stream(self.device)
# 同步设备
torch.cuda.synchronize(self.device)
# 设置新流
self.stream.synchronize()
torch.cuda.set_stream(self.stream)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
# 同步流
self.stream.synchronize()
# 恢复原始流
torch.cuda.set_stream(self.original_stream)
# 同步设备
torch.cuda.synchronize(self.device)
这个类实现了 __enter__ 和 __exit__ 方法,提供了更复杂的上下文管理功能,特别适合需要精确控制 CUDA 流的场景。
嵌套上下文的工作原理
当使用多重嵌套上下文时,工作流程如下:
- 按从外到内的顺序调用每个上下文管理器的
__enter__方法 - 执行
with块中的代码 - 按从内到外的顺序调用每个上下文管理器的
__exit__方法
这确保了资源和状态的正确设置和清理顺序,即使在异常发生时也是如此:
# 嵌套上下文的工作流程
# 1. memory_context.__enter__()
# 2. graph_context.__enter__()
# 3. profile_context.__enter__()
# 4. 执行代码块
# 5. profile_context.__exit__()
# 6. graph_context.__exit__()
# 7. memory_context.__exit__()
with cuda_memory_context():
with GraphContext(device) as graph:
with cuda_profiler.record("operation"):
# 执行代码
model.forward(inputs)
即使在代码执行期间发生异常,所有上下文管理器的 __exit__ 方法仍会被调用,确保资源得到正确清理。
实际应用案例
在 vLLM 的 capture_model 方法中,多重上下文管理器确保了 CUDA 图捕获的正确环境:
@torch.inference_mode()
def capture_model(self, kv_caches: List[List[torch.Tensor]]) -> None:
# ...准备工作...
# 多重上下文管理器
with self.attn_state.graph_capture(max_batch_size), \
graph_capture(self.device) as graph_capture_context, \
set_forward_context(attn_metadata, self.config, virtual_engine):
for batch_size in cudagraph_capture_sizes:
# ...准备捕获输入...
# 创建并捕获图
graph_runner = CUDAGraphRunner(device=self.device)
graph_runner.capture(**capture_inputs)
# 保存图
self.graph_runners[batch_size] = graph_runner
每个上下文管理器负责特定方面:
self.attn_state.graph_capture准备注意力状态graph_capture设置 CUDA 流和同步点set_forward_context配置前向传播环境
总的来说,上下文管理器在 vLLM 中扮演着关键角色,提供了优雅的资源管理和状态控制机制,确保了复杂操作(如 CUDA 图捕获)的正确执行环境,同时简化了错误处理和资源清理。这种机制对于管理 GPU 资源和确保系统稳定性特别重要。
7. 性能优化与最佳实践
7.1 示例应用:构建高性能API服务
vLLM可以轻松构建高性能的LLM API服务,以下是一个完整的示例:
from fastapi import FastAPI, BackgroundTasks
from pydantic import BaseModel, Field
from typing import List, Optional
from vllm import LLM, SamplingParams
import uvicorn
import asyncio
app = FastAPI(title="高性能LLM API服务")
# 初始化模型(在生产环境中应使用更完整的配置)
llm = LLM(
model="llama-7b",
tensor_parallel_size=2, # 使用2个GPU进行张量并行
gpu_memory_utilization=0.8,
max_num_seqs=256, # 批处理大小
)
class GenerationRequest(BaseModel):
prompt: str
max_tokens: int = Field(default=128)
temperature: float = Field(default=0.7)
top_p: float = Field(default=0.9)
stream: bool = Field(default=False)
class GenerationResponse(BaseModel):
text: str
usage: dict
@app.post("/generate", response_model=GenerationResponse)
async def generate(request: GenerationRequest):
# 设置采样参数
params = SamplingParams(
max_tokens=request.max_tokens,
temperature=request.temperature,
top_p=request.top_p,
)
# 异步执行生成
outputs = await asyncio.to_thread(
llm.generate, [request.prompt], params
)
# 构建响应
response = GenerationResponse(
text=outputs[0].outputs[0].text,
usage={
"prompt_tokens": len(outputs[0].prompt_token_ids),
"completion_tokens": len(outputs[0].outputs[0].token_ids),
"total_tokens": len(outputs[0].prompt_token_ids) +
len(outputs[0].outputs[0].token_ids)
}
)
return response
# 添加健康检查端点
@app.get("/health")
async def health_check():
return {"status": "healthy"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
这个服务具有以下特点:
- 高并发处理:利用vLLM的批处理能力处理多个并发请求
- 资源高效利用:通过张量并行和内存优化最大化GPU利用率
- 生产级API:提供标准的REST API接口,兼容其他LLM服务形式
- 性能监控:可以通过添加中间件来监控请求延迟和吞吐量
7.2 性能优化策略
7.2.1 批处理优化
vLLM通过连续批处理(Continuous Batching)技术显著提高了吞吐量:
- 静态批处理的局限:传统批处理要求所有序列同时启动和结束,长序列会使短序列等待,导致GPU利用率低
- 连续批处理优势:允许动态添加和移除序列,提高GPU利用率达80-90%
- 实现方法:
# 优化批处理代码示例 def _prepare_batch(self, scheduled_seq_groups): batch = Batch() # 动态收集当前活跃序列 for seq_group in scheduled_seq_groups: batch.add_sequence_group(seq_group) # 处理不同长度的序列 return batch.finalize()
7.2.2 内存优化
- PagedAttention:将KV缓存组织为固定大小的物理块,通过块表映射实现高效内存管理
- 量化技术:支持INT8/INT4量化,可将模型内存需求减少50-75%
- 激活检查点:在推理中重计算某些中间结果,而非全部保存,平衡计算和内存使用
- 内存使用监控:动态调整批大小和缓存策略,避免OOM错误
7.2.3 计算优化
- CUDA图优化:预先捕获和优化GPU操作序列,降低CPU-GPU通信开销
- 自定义CUDA核心:针对PagedAttention实现了高效的CUDA核心
- 张量并行:将大型模型分割到多个GPU上执行
- 异步执行:利用流水线执行和异步通信提高并发性
7.3 部署最佳实践
7.3.1 硬件选择与配置
- GPU选择:推荐使用支持CUDA的NVIDIA GPU,如A100、H100系列
- 内存配置:
- 计算模型内存需求:
模型大小 + 批处理KV缓存 + 激活内存 - 对于14B模型,推荐至少40GB显存
- 计算模型内存需求:
- CPU配置:CPU核心数影响分词和后处理性能,建议每个GPU配置4-8个CPU核心
7.3.2 系统参数调优
- 批处理大小:根据模型大小和GPU内存动态调整
# 批处理大小计算示例 max_batch_size = (gpu_memory_gb * 0.9 - model_size_gb) // ( token_kv_cache_size_gb * max_seq_len) - 块大小:KV缓存的物理块大小,默认16,可根据应用场景调整为8-32
- 预分配缓存:对于固定工作负载,预分配缓存可减少动态分配开销
engine = LLMEngine( model="llama-7b", block_size=16, gpu_memory_utilization=0.9, swap_space=4, # GB )
7.3.3 分布式部署
- 单机多GPU:优先使用张量并行,设置
tensor_parallel_size参数 - 多机部署:确保机器间高速网络连接(推荐InfiniBand或100Gb以太网)
- 负载均衡:使用轮询或最小负载策略分发请求
7.3.4 常见性能问题及解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| GPU利用率低 | 批处理大小不足 | 增加max_num_seqs或max_num_batched_tokens |
| 内存溢出 (OOM) | KV缓存过大 | 减小批大小或启用缓存压缩 |
| 高延迟 | CPU瓶颈 | 增加CPU核心或优化分词逻辑 |
| 吞吐量不足 | CUDA图未启用 | 确保disable_cuda_graphs=False |
| 输入处理慢 | Tokenizer配置 | 使用快速分词器或预处理批量输入 |
7.4 常见问题与解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| GPU利用率低 | 批处理大小不足 | 增加max_num_seqs或max_num_batched_tokens |
| 内存溢出 (OOM) | KV缓存过大 | 减小批大小或启用缓存压缩 |
| 高延迟 | CPU瓶颈 | 增加CPU核心或优化分词逻辑 |
| 吞吐量不足 | CUDA图未启用 | 确保disable_cuda_graphs=False |
| 输入处理慢 | Tokenizer配置 | 使用快速分词器或预处理批量输入 |
8. 总结与展望
8.1 技术创新点总结
vLLM作为高性能大语言模型推理框架,其核心创新点包括:
| 技术创新 | 核心价值 | 实现方式 |
|---|---|---|
| PagedAttention | 解决KV缓存内存碎片问题 | 将连续logical序列映射到不连续物理内存块 |
| 连续批处理 | 提高GPU利用率 | 动态调度机制允许序列独立进出批处理队列 |
| CUDA图捕获 | 减少CPU-GPU通信开销 | 预编译和优化GPU操作序列 |
| 分布式推理 | 支持超大模型部署 | 实现张量并行和流水线并行 |
| 动态加载卸载 | 高效内存管理 | 通过Python反射机制实现按需加载 |
vLLM通过上述创新,在保持API简洁性的同时,实现了高达4倍的性能提升,以及更高效的内存使用。其设计理念体现了现代软件工程的最佳实践,包括:
- 模块化设计:清晰的组件分离使得系统易于扩展和维护
- 抽象接口:通过抽象接口隔离实现细节,支持多种硬件后端
- 高级语言特性:巧妙利用Python的动态特性实现灵活配置和加载
- 并发与并行:多层次的并行策略最大化硬件利用率
8.2 与其他框架对比
以下是vLLM与其他主流LLM推理框架的对比:
| 特性 | vLLM | HuggingFace TGI | DeepSpeed-Inference | TensorRT-LLM |
|---|---|---|---|---|
| 连续批处理 | ✅ | ✅ | ❌ | ✅ |
| PagedAttention | ✅ | ❌ | ❌ | ❌ |
| 张量并行 | ✅ | ✅ | ✅ | ✅ |
| 流水线并行 | ✅ | ❌ | ✅ | ✅ |
| 量化支持 | INT8/INT4 | INT8 | INT8/INT4 | INT8/INT4/FP8 |
| 自定义模型支持 | 中等 | 高 | 中等 | 低 |
| 开发难度 | 低 | 低 | 高 | 高 |
| 性能表现 | 优秀 | 良好 | 优秀 | 极佳 |
| 部署复杂度 | 低 | 低 | 高 | 高 |
| 社区活跃度 | 高 | 高 | 中 | 中 |
vLLM在易用性和性能之间取得了良好平衡,特别适合快速部署和优化大语言模型服务。
8.3 未来发展趋势
根据vLLM的发展轨迹和大语言模型服务的行业需求,可以预见以下发展方向:
8.3.1 技术演进方向
- 更多硬件后端支持:扩展到AMD/Intel GPU和专用AI加速器
- 混合精度推理:根据不同层的敏感性动态调整精度
- 分布式推理增强:改进跨数据中心的模型部署效率
- 自适应批处理:基于负载动态调整批处理策略
- 内存优化:KV缓存压缩和选择性保存
- 推理时微调:支持推理过程中的参数高效微调
8.3.2 应用场景扩展
- 边缘设备部署:优化小型设备上的模型运行效率
- 多模态支持:扩展框架以支持图像、音频等多模态输入
- 专用场景优化:为RAG、Agent等应用场景提供专门优化
- 服务化增强:提供更完善的监控、扩缩容和灾备功能
8.4 实践建议
对于开发者和研究人员,建议从以下几个方面入手深入理解和应用vLLM:
- 从小模型开始实践:先用较小模型熟悉API和工作流程
- 理解内存分配机制:掌握PagedAttention的核心原理
- 性能分析与调优:学习使用profiler工具分析性能瓶颈
- 扩展自定义功能:基于vLLM架构开发特定应用场景的优化
- 关注社区动态:vLLM发展迅速,定期关注新特性和优化
通过深入理解vLLM的设计理念和技术实现,开发者可以更好地应用和扩展这一框架,为大语言模型的落地应用提供强有力的技术支持。
附录
A. 关键源码目录结构
vllm/
├── config.py # 配置类定义
├── engine/ # 核心引擎
│ ├── arg_utils.py # 参数处理
│ ├── async_llm_engine.py # 异步引擎
│ └── llm_engine.py # LLM引擎主类
├── entrypoints/ # 入口点
│ ├── api_server.py # API服务器
│ ├── llm.py # 命令行接口
│ └── openai.py # OpenAI兼容API
├── executor/ # 执行器
│ ├── executor_base.py# 执行器基类
│ └── schedulers/ # 调度器
├── model_executor/ # 模型执行器
│ ├── layers/ # 模型层实现
│ └── models/ # 模型定义
├── sampling/ # 采样策略
│ ├── sampling_params.py # 采样参数
│ └── samplers.py # 采样器实现
├── sequence.py # 序列管理
├── worker/ # 工作节点
│ ├── model_runner.py # 模型运行器
│ └── worker.py # 工作节点实现
└── utils.py # 工具函数